Сказать "Спасибо"

1 Материалы по курсу «Основы телекоммуникационных технологий»
В данном разделе приводятся детальные описания по нескольким темам теоретической части занятий по данному курсу. Полный набор тем примерно следующий:
§ Ethernet. Структура кадра Ethernet
§ Протокол IP и адресация
§ Маршрутизация. Принцип работы маршрутизатора
§ Стек протоколов TCP/IP
§ Технология VLAN. Протокол STP
§ Изучение TCP/IP на примерах. Защита от хакеров
§ Некоторые методы защиты: NAT/PAT, списки доступа, прокси
§ Система доменных имен DNS
§ Основные понятия глобальных сетей. Первичные сети. PDH/SDH.
§ Протоколы SLIP, HDLC, PPP.
§ Технологии глобальных сетей: ISDN, B-ISDN,
§ Технологии глобальных сетей: ATM, Frame Relay,
§ Технологии глобальных сетей: xDSL, SONET/SDH.
§ Структура и алгоритмы работы провайдеров телекоммуникационных услуг.
§ Телекоммуникационные сервисы и их автоматизация. OSS/BSS.
§ Современные сервисы и технологии: IP/MPLS, VPN
§ Современные сервисы и технологии: Voice over IP, TDM over IP
1.1 Ethernet. Структура кадра Ethernet
1.1.1 История создания
Ethernet (эзернет, от лат. aether — эфир) — пакетная технология компьютерных сетей. Стандарты Ethernet определяют проводные соединения и электрические сигналы на физическом уровне, формат пакетов и протоколы управления доступом к среде — на канальном уровне модели OSI. Ethernet в основном описывается стандартами IEEE группы 802.3.
Ethernet стал самой распространённой технологией LAN в середине 90-х годов прошлого века, вытеснив такие технологии, как Arcnet, FDDI и Token ring.
В 1979 году- Digital, Intel и Xerox (DIX) создают сеть Ethernet II. В 1980 результаты были представлены в IEEE. На основе представленных результатов в 1983 году создается новый стандарт IEEE802.3.
1.1.2 Сравнение стандартов Ethernet II и IEEE 802.3
|
|
Протокол доступа к среде |
Физический уровень OSI |
Канальный уровень OSI |
Поля в заголовке кадра |
Контроль ошибок |
Макс./мин. размер кадра (байт) |
|
Ethernet II |
CSMA /CD |
10BASE-5
|
Занимает весь канальный уровень |
Dest . mac адрес, source mac адрес, TYPE. |
FCS |
64/1518 |
|
IEEE 802.3 |
CSMA /CD |
10BASE-5 (в начальном варианте) |
Разбит на 2 подуровня: МАС и LLC. IEEE 802.3 соответствует MAC подуровню. |
Dest . mac address, source mac address, LENGTH. |
FCS |
64/1518 |
Технология
В стандарте указано, что в качестве передающей среды используется коаксиальный кабель, метод управления доступом — множественный доступ с контролем несущей и обнаружением столкновений, скорость передачи данных 10 Мбит/с, размер пакета от 72 до 1526 байт (с учетом преамбулы), описаны методы кодирования данных.
Количество узлов в одном разделяемом сегменте сети ограничено предельным значением в 1024 рабочих станции (спецификации физического уровня могут устанавливать более жёсткие ограничения, например, к сегменту тонкого коаксиала может подключаться не более 30 рабочих станций, а к сегменту толстого коаксиала — не более 100). Однако сеть, построенная на одном разделяемом сегменте, становится неэффективной задолго до достижения предельного значения количества узлов.
Развитие этой технологии для сетей 100 Мбит/с получило название Fast Ethernet, для 1000 Мбит/с — Gigabit Ethernet.
Ранние модификации Ethernet
Xerox Ethernet — оригинальная технология, скорость 3Мбит/с, существовала в двух вариантах Version 1 и Version 2, формат кадра последней версии до сих пор имеет широкое применение.
10BROAD36 — широкого распространения не получил. Один из первых стандартов, позволяющий работать на больших расстояниях. Использовал технологию широкополосной модуляции, похожей на ту, что используется в кабельных модемах. В качестве среды передачи данных использовался коаксиальный кабель.
1BASE5 — также известный, как StarLAN, стал первой модификацией Ethernet-технологии, использующей витую пару. Работал на скорости 1 Мбит/с, но не нашёл коммерческого применения.
10 Мбит/с Ethernet
10BASE5, IEEE 802.3 (называемый также «Толстый Ethernet») — первоначальная разработка технологии со скоростью передачи данных 10 Мбит/с. Следуя раннему стандарту IEEE использует коаксиальный кабель, с волновым сопротивлением 50 Ом (RG-8), с максимальной длиной сегмента 500 метров.
10BASE2, IEEE 802.3a (называемый «Тонкий Ethernet») — используется кабель RG-58, с максимальной длиной сегмента 200 метров, компьютеры присоединялись один к другому, для подключения кабеля к сетевой карте нужен T-коннектор, а на кабеле должен быть BNC-коннектор. Требуется наличие терминаторов на каждом конце. Многие годы этот стандарт был основным для технологии Ethernet.
StarLAN 10 — Первая разработка, использующая витую пару для передачи данных на скорости 10 Мбит/с. В дальнейшем, эволюционировал в стандарт 10BASE-T.
10BASE-T, IEEE 802.3i — для передачи данных используется 4 провода кабеля витой пары (две скрученные пары) категории-3 или категории-5. Максимальная длина сегмента 100 метров.
FOIRL — (акроним от англ. Fiber-optic inter-repeater link). Базовый стандарт для технологии Ethernet, использующий для передачи данных оптический кабель. Максимальное расстояние передачи данных без повторителя 1км.
10BASE-F, IEEE 802.3j — Основной термин для обозначения семейства 10 Мбит/с ethernet-стандартов использующих оптоволоконный кабель на расстоянии до 2 километров: 10BASE-FL, 10BASE-FB и 10BASE-FP. Из перечисленного только
Быстрый Ethernet (100 Мбит/с) (Fast Ethernet)
100BASE-T — Общий термин для обозначения одного из трёх стандартов 100 Мбит/с Ethernet, использующий в качестве среды передачи данных витую пару. Длина сегмента до 100 метров. Включает в себя 100BASE-TX, 100BASE-T4 и 100BASE-T2.
100BASE-TX, IEEE 802.3u — Развитие технологии 10BASE-T, используется топология звезда, задействованы две пары кабеля ктегории-5, максимальная скорость передачи данных 100 Мбит/с.
100BASE-FX — 100 Мбит/с Ethernet с помощью оптоволоконного кабеля. Максимальная длина сегмента 400 метров в полудуплексном режиме (для гарантированного обнаружения коллизий) или 2 километра в дуплексном режиме передачи данных.
Гигабит Ethernet
1000BASE-T, IEEE 802.3ab — Стандарт Ethernet 1 Гбит/с. Используется витая пара категории 5e или категории 6. В передаче данных участвуют все 4 пары. Скорость передачи данных — 250Мбит/с по одной паре.
1000BASE-TX, — Стандарт Ethernet 1 Гбит/с, использующий только витую пару категории 6. Практически не используется.
1000Base-X — общий термин для обозначения технологии Гигабит Ethernet, использующей в качестве среды передачи данных оптоволоконный кабель, включает в себя 1000BASE-SX, 1000BASE-LX и 1000BASE-CX.
1000BASE-SX, IEEE 802.3z — 1 Гбит/с Ethernet технология, использует многомодовое волокно дальность прохождения сигнала без повторителя до 550 метров.
1000BASE-LX, IEEE 802.3z — 1 Гбит/с Ethernet технология, использует многомодовое волокно дальность прохождения сигнала без повторителя до 550 метров. Оптимизирована для дальних расстояний, при использовании одномодового волокна (до 10 километров).
1000BASE-CX — Технология Гигабит Ethernet для коротких расстояний (до 25 метров), используется специальный медный кабель (Экранированная витая пара (STP)) с волновым сопротивлением 150 Ом. Заменён стандартом 1000BASE-T, и сейчас не используется.
1000BASE-LH (Long Haul) — 1 Гбит/с Ethernet технология, использует одномодовый оптический кабель, дальность прохождения сигнала без повторителя до 100 километров.
|
Интерфейс физического уровня |
Тип кабеля
|
Максимальная протяженность (в скобках диаметр волокна) |
Типичные приложения
|
|
1000BaseSX |
Многомодовый кабель с коротковолновым лазером (850 нм) |
220 м (62,5 мкм); 500 м (50 мкм) |
Короткие магистрали |
|
1000BaseLX
|
Многомодовый и одномодовый кабель с длинноволновым лазером (1300 нм) |
Многомодовый: 550 м (62,5 мкм);550 м (50 мкм) Одномодовый: 5 км (9 мкм) |
Короткие магистрали Территориальные магистрали
|
|
1000BaseCX
|
Короткий медный кабель (STP/коаксиал)
|
25 м
|
Межсоединение оборудования в монтажном шкафу |
|
1000BaseT
|
4-парный неэкранированный Категории 5 |
100 м
|
Горизонтальные трассы
|
10 Гигабит Ethernet (для справки)
Новый стандарт 10 Гигабит Ethernet включает в себя семь стандартов физической среды для LAN, MAN и WAN. В настоящее время он описывается поправкой IEEE 802.3ae и должен войти в следующую ревизию стандарта IEEE 802.3.
10GBASE-CX4 — Технология 10 Гигабит Ethernet для коротких расстояний (до 15 метров), используется медный кабель CX4 и коннекторы InfiniBand.
10GBASE-SR — Технология 10 Гигабит Ethernet для коротких расстояний (до 26 или 82 метров, в зависимости от типа кабеля), используется многомодовое оптоволокно. Он также поддерживает расстояния до 300 метров с использованием нового многомодового оптоволокна (2000 МГц/км).
10GBASE-LX4 — использует уплотнение по длине волны для поддержки расстояний от 240 до 300 метров по многомодовому оптоволокну. Также поддерживает расстояния до 10 километров при использовании одномодового оптоволокна.
10GBASE-LR и 10GBASE-ER — эти стандарты поддерживают расстояния до 10 и 40 километров соответственно.
10GBASE-SW, 10GBASE-LW и 10GBASE-EW — Эти стандарты используют физический интерфейс, совместимый по скорости и формату данных с интерфейсом OC-192 / STM-64 SONET/SDH. Они подобны стандартам 10GBASE-SR, 10GBASE-LR и 10GBASE-ER соответственно, так как используют те же самые типы кабелей и расстояния передачи.
10GBASE-T — Использует неэкранированную витую пару. Должен быть готов к августу 2006.
1.1.3 Формат кадра
Существует несколько форматов Ethernet-кадра.
Формат кадра Ethernet II
-Преамбула – 7 байт, для синхронизации, (101010101010…)
-SOF – start of frame delimiter, 1 байт, начало кадра (101001011)
-FCS - frame check sequence, 4 байта, поле контрольной последовательности фрейма
-Destination Address – Ethernet адрес получателя, 6 байт
-Source Address – Ethernet адрес отправителя, 6 байт
-Type – тип, для обозначения типа протокола уровня 3 (0080 hex – ip)
-Length – длина, фактически необязательна, т.к. между кадрами есть задержка (не используется в Ethernet 2)
Минимальный размер кадра (после SOF) – 64 байта.
Различные форматы:
Первоначальный Variant I (больше не применяется).
Ethernet Version 2 или Ethernet-кадр II, ещё называемый DIX (аббревиатура первых букв фирм-разработчиков DEC, Intel, Xerox) — наиболее распространена и используется по сей день. Часто используется непосредственно протоколом Интернет.
Кадр IEEE802.3
Novell — внутренняя модификация IEEE 802.3 без LLC (Logical Link Control).
LLC часть канального уровня определяет работу протокола IEEE802.2
Разные кадры LLC:
Кадр IEEE 802.2 LLC.
Кадр IEEE 802.2 LLC/SNAP.
В качестве дополнения, Ethernet-кадр кадр может содержать тег IEEE 802.1Q, для идентификации VLAN к которой он адресован и IEEE 802.1p для указания приоритетности.
Отличие Ethernet II и IEEE 802.3:


Пример IEEE802.3/IEEE802.2 в Ethereal

Пример кадра Ethernet v.2 в Ethereal:

Пояснения:
Институт IEEE разделил канальный уровень на 2 подуровня: LLC (Logical Link Control) и уровень MAC (Medium Access Control). Обычный Ethernet (V2) работает на уровнях физическом и канальном (OSI), спецификация IEEE 802.3 определяет работу лишь на физическом и части канального (MAC) уровне. Работу на уровне LLC определяет спецификация IEEE 802.2.
Базовые пакеты Ethernet II и IEEE 802.3 имеют одинаковую структуру. Их различие - в назначении 13-го и 14-го байтов: поля типа протокола и длины кадра соответственно. Совместное использование разных форматов кадров в одном сегменте Ethernet благодаря тому, что тип протокола характеризуется числом, большим 0x05FE.
В спецификации IEEE тип вышележащего протокола передается в кадре протокола 802.2
Поля DSAP и SSAP служат для определения вышележащего протокола и, как правило, содержат одно и то же значение. Управляющее поле обычно задается равным 0x03 (в соответствии с протоколом LLC это означает, что соединение на канальном уровне не устанавливается).
1.1.4 MAC адресация

-Записывается в заголовке канального уровня (source, destination)
-Используется для физической адресации
-Уникален
-Широковещательный mac-address FF FF FF FF FF FF
1.1.5 FCS
Frame Check Sequence, FCS - вычисляется на основе содержимого заголовка и данных (вместе с заполнителем, но без учета преамбулы и ограничителя) с помощью 32-разрядного циклического избыточного кода (Cyclic Redundancy Code, CRC-32)
Данный код позволяет обнаружить 99,999999977% всех ошибок в сообщениях длиной до 64 байт
1.1.6 Метод CSMA/CD
SEND:

RECEIVE:

1.1.7 Алгоритм вычисления задержки между попытками
– Количество слотовых времен (интервалов по 51,2 мкс), которое станция ждет перед тем как совершить N-ую попытку передачи (N-1 попыток потерпели фиаско из-за возникновения коллизий во время передачи) представляет случайное целое число с однородной функцией распределения в интервале
0<=R<=2^K, где K = min (N, BL)
BL (back off limit) - установленная стандартом величина, равная 10.
Если количество последовательных безуспешных попыток отправить кадр доходит до 16, то есть коллизия возникает 16 раз подряд, то кадр сбрасывается
1.1.8 Методика расчета сети Ethernet (10BASE)
– По стандарту IEEE 802.3 узел не может предавать очень короткие кадры. Минимальная длина поля без преамбулы (и SOF) – 64 байта. С преамбулой получается 576 бит.
– RTD – round-trip delay, задержка на двойном пробеге. В более общем случае RTD определяет суммарную задержку, связанную как с задержкой из-за конечной длины сегментов, так и с задержкой, возникающей при обработке кадров на физическим уровнем промежуточных повторителей и оконечных узлов сети.
– BT – bit time, битовое время. Время в 1 BT соответствует времени, необходимому для передачи одного бита, т.е. 0,1 мкс при скорости 10 Мбит/с.
Для того, чтобы передающая станция смогла понять, что произошла коллизия до того, как кадр минимальной длины будет отправлен необходимо выполнение следующего условия:
RTD < 576 BT
(это необходимо для того, чтобы станция повторила попытку передачи, в противном случае, протокол Ethernet передающей станции будет считать, что попытка была успешной и начнет передачу следующего кадра).
1.1.9 Правило 5/4/3 (для 10base)
– Правила использования повторителей (Ethernet Repeater).
Между любыми двумя взаимодействующими узлами сети может находиться до 5 сегментов, соединенных не более, чем 4 повторителями (или хабами). При этом компьютеры (узлы сети) могут находиться не более, чем в 3 сегментах из 5. Оставшиеся два сегмента не должны содержать компьютеров и служат лишь для удлинения сети (соединения повторителей или концентраторов). В каждом конце пустого сегмента находится повторитель или хаб.
Замечание:
Данные ограничения (и ограничение на длину сегмента и правило 5/4/3) связано с наличием коллизий. В современных сетях при использовании физической топологии звезда (витая пары, оптика) с Ethernet коммутаторами в качестве центральных элементов коллизионный домен сводится к 2 элементам (порт коммутатора - сетевое устройство) в случае half-duplex или к полному устранению коллизий в случае full duplex (Это явление называется микро сегментацией). Поэтому эти ограничения не имеют силу. Но все таки это знание полезно, во-первых, потому, что повторители популярны и используются и по сей день и являются одним из основных элементов сети, а во-вторых, – эти примеры дают представления об ограничениях, объективно возникающих при использовании протоколов и технологий, работающих по методу CSMA/CD.
1.1.10 Кодирование
– Манчестерский код (используется в 10BASE).
Для кодирования нулей и единиц используется перепад потенциала, то есть кодирование осуществляется фронтом импульса. Перепад потенциала происходит на середине тактового импульса, при этом единица кодируется перепадом от низкого потенциала к высокому, а нуль — наоборот. В начале каждого такта в случае появления нескольких нулей или единиц подряд может возникать служебный перепад потенциала.
Это решает проблему синхронизации длинных последовательностей нулей или единиц.

Многозначность понятия “топология”
– Физическая. В этом случае конфигурация физических связей определяется электрическими соединениями компьютеров, то есть ребрам графа соответствуют отрезки кабеля, связывающие пары узлов.
– Логическая топология (то есть структура связей, характер распространения сигналов по сети). Это, наверное, наиболее правильное определение топологии.
– Топология управления обменом (то есть принцип и последовательность передачи права на захват сети между отдельными компьютерами).
– Информационная топология (то есть направление потоков информации, передаваемой по сети).
Пример: 100Base-TX – физическая топология звезда, логическая шина.
1.1.11 Сетевые анализаторы
Одним из инструментов при выполнении лабораторных работ являются сетевые анализаторы. Предлагается использовать анализатор трафика Ethereal. Так же в работах используется программный продукт pcap (в случае windows версия pcap для этой операционной системы – WinPcap). На основе этого продукта написаны две программы, позволяющие отправлять в сеть произвольные кадры. Это является инструментом для более глубокого анализа работы сетевых протоколов.
WinPcap позволяет в операционной системе семейства Windows получать и отсылать кадры в обход “законной” процедуры отправки и получения пактов, например в обход стека TCP/IP
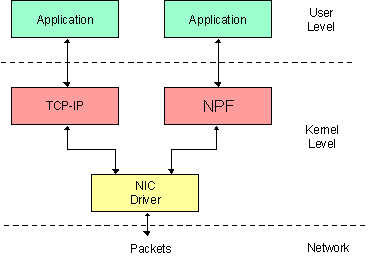
Это позволяет нам отсылать произвольный набор нулей и единиц. Это может быть использовано например для отправки пакетов с произвольным ip адресом, произвольным mac адресом.
При “ловле” пакетов” сетевой адаптер выставляется в “promiscuous mode”, что приводит к тому, что система “ловит” все пакеты, которые “слышит”.
Программа Ethereal работает “поверх” winpcap, предоставляя удобный интерфейс пользователя.

Отображение структуры кадра в Ethereal:
В данном примере нужно обратить внимание на отражение следующих свойств протоколов Ethernet, стека TCP/IP:
Тип Ethernet – Ethernet II
Инкапсуляция
Структура заголовка кадра 1. Source mac 2. Destination mac3. Type – тип вышележащего протокола
Горизонтальная и вертикальная составляющая модели OSI на примере заголовка канального уровня.
Пример заголовка сетевого уровня в Ethereal

1.1.12 Сетевые устройства
Повторитель.
Устройство первого уровня модели OSI. Сигнал, полученный на порту, посылается во все порты. Может происходить усиление и восстановление сигнала. Может происходить преобразование сигнала, если существуют несколько портов, работающих по разным (но принципиально схожим) протоколам, например, 10Base-T и 100Base-TX. При этом не происходит какой-либо анализ структуры кадра или pdu более высокого уровня OSI. Поступающий сигнал воспринимается как битовый поток, поэтому это устройство относится к устройствам первого уровня OSI.
Коммутатор.
Устройство второго уровня модели OSI. Анализирует информацию канального уровня. Строит таблицу соответствия mac адреса – порту. В этой таблице содержится информация о том, какие мас адреса коммутатор “услышал” на этом порту. В дальнейшем эта информация используется для пересылки кадра только в соответствующий порт.
Последовательность действий.
1.На один из своих портов коммутатор получает кадр. В зависимости от метода коммутации, который он использует, коммутатор либо считывает весь кадр в приемный буфер, после чего начинает анализ информации канального уровня либо считывает только часть кадра, пытаясь перенаправить кадр на нужный порт “на лету”. Но во всех случаях switch считывает и анализирует destination и source mac address.
2. Прочитав destination mac address, switch проверяет таблицу соответствия mac адресов – портов. Если этот mac адрес есть – то кадр отправляется в соответствующий порт. Если нет, то рассылается во все портам. При этом, если используется динамический способ построения таблицы соответствия, то source mac address записывается в таблицу, при этом портом является тот порт, на который был получен кадр.
3. Если destination mac address отсутствовал в таблице соответствия и в соответствии с п.2 этот кадр был направлен на все порты, то, если найдется устройство с соответствующим mac адресом, то обратный кадр приведет к тому, что этот mac адрес появится в таблице и все последующие кадры будут направлены в соответствующий порт.
4. Широковещательные кадры посылаются во все порты.
Замечание: этот алгоритм относится к случаю, когда нет vlan и когда выбран режим динамического определения mac адресов.
1.2 Протокол IP и адресация
1.2.1 Введение
Протокол IP работает на третьем – сетевом уровне – модели OSI.
Напомним, что сетевой уровень заведует движением информации по сетям, состоящим из нескольких или многих сегментов. Для успешного решения этой задачи в протокол данного уровня вносится информация о логическом адресе источника и адресата пакета. При прохождении пакетов через узлы, соединяющие различные сети, эта информация анализируется и пакет пересылается к следующему узлу, принадлежащему уже к другому сегменту. Информация о том, куда пересылать пакет, может содержаться в таблицах устройства, выполняющего роль маршрутизатора, или вычисляться в реальном времени (что делается значительно реже). Таким образом, переходя от узла к узлу, пакеты путешествуют по сети. В функции сетевого уровня входят также идентификация и удаление «заблудившихся» пакетов, то есть таких, которые прошли через некоторое число узлов, но так и не попали к адресату.
Функции протокола IP определены в стандарте RFC-791 следующим образом: “Протокол IP обеспечивает передачу блоков данных, называемых дейтаграммами, от отправителя к получателям, где отправители и получатели являются компьютерами, идентифицируемыми адресами фиксированной длины (IP-адресами). Протокол IP обеспечивает при необходимости также фрагментацию и сборку дейтаграмм для передачи данных через сети с малым размером пакетов”.
Протокол IP является ненадежным протоколом без установления соединения. Это означает, что протокол IP не подтверждает доставку данных, не контролирует целостность полученных данных и не производит операцию квитирования (handshaking) - обмена служебными сообщениями, подтверждающими установку соединения с узлом назначения и его готовность к приему данных. Протокол IP обрабатывает каждую дейтаграмму как независимую единицу, не имеющую связи ни с какими другими дейтаграммами в Интернет. После того, как дейтаграмма отправляется в сеть, ее дальнейшая судьба никак не контролируется отправителем (на уровне протокола IP). Если дейтаграмма не может быть доставлена, она уничтожается.
Рассмотрим более подробно принцип работы протокола.
1.2.2 Заголовки 2 и 3 уровней
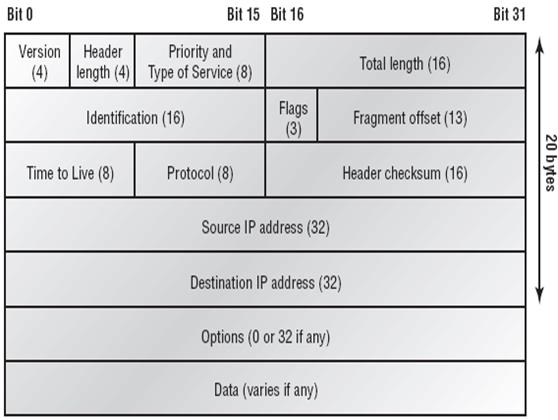
Рис. 1
Пакет IP состоит из заголовка и поля данных (см. рис. 1). Заголовок пакета имеет следующие поля:
1. Поле Номер версии (Version) указывает версию протокола IP. Сейчас повсеместно используется версия 4 и готовится переход на версию 6, называемую также IPng (IP next generation).
2. Поле Длина заголовка (Header length) пакета IP занимает 4 бита и указывает значение длины заголовка, измеренное в 32-битовых словах. Обычно заголовок имеет длину в 20 байт (пять 32-битовых слов), но при увеличении объема служебной информации эта длина может быть увеличена за счет использования дополнительных байт в поле Резерв (IP OPTIONS).
3. Поле Тип сервиса (Priority and Type of Service) занимает 1 байт и задает приоритетность пакета и вид критерия выбора маршрута. Первые три бита этого поля образуют подполе приоритета пакета (PRECEDENCE). Приоритет может иметь значения от 0 (нормальный пакет) до 7 (пакет управляющей информации). Маршрутизаторы и компьютеры могут принимать во внимание приоритет пакета и обрабатывать более важные пакеты в первую очередь. Поле Тип сервиса содержит также три бита, определяющие критерий выбора маршрута. Установленный бит D (delay) говорит о том, что маршрут должен выбираться для минимизации задержки доставки данного пакета, бит T - для максимизации пропускной способности, а бит R - для максимизации надежности доставки.
4. Поле Общая длина (Total Length) занимает 2 байта и указывает общую длину пакета с учетом заголовка и поля данных.
5. Поле Идентификатор пакета (Identification) занимает 2 байта и используется для распознавания пакетов, образовавшихся путем фрагментации исходного пакета. Все фрагменты должны иметь одинаковое значение этого поля.
6. Поле Флаги (Flags) занимает 3 бита, оно указывает на возможность фрагментации пакета (установленный бит Do not Fragment - DF - запрещает маршрутизатору фрагментировать данный пакет), а также на то, является ли данный пакет промежуточным или последним фрагментом исходного пакета (установленный бит More Fragments - MF - говорит о том пакет переносит промежуточный фрагмент).
7. Поле Смещение фрагмента (Fragment Offset) занимает 13 бит, оно используется для указания в байтах смещения поля данных этого пакета от начала общего поля данных исходного пакета, подвергнутого фрагментации. Используется при сборке/разборке фрагментов пакетов при передачах их между сетями с различными величинами максимальной длины пакета.
8. Поле Время жизни (TIME TO LIVE) занимает 1 байт и указывает предельный срок, в течение которого пакет может перемещаться по сети. Время жизни данного пакета измеряется в секундах и задается источником передачи средствами протокола IP. На шлюзах и в других узлах сети по истечении каждой секунды из текущего времени жизни вычитается единица; единица вычитается также при каждой транзитной передаче (даже если не прошла секунда). При истечении времени жизни пакет аннулируется.
9. Идентификатор Протокола верхнего уровня (PROTOCOL) занимает 1 байт и указывает, какому протоколу верхнего уровня принадлежит пакет (например, это могут быть протоколы TCP, UDP или RIP).
10. Контрольная сумма (HEADER CHECKSUM) занимает 2 байта, она рассчитывается по всему заголовку.
11. Поля Адрес источника (SOURCE IP ADDRESS) и Адрес назначения (DESTINATION IP ADDRESS) имеют одинаковую длину - 32 бита, и одинаковую структуру.
12. Поле Резерв (IP OPTIONS) является необязательным и используется обычно только при отладке сети. Это поле состоит из нескольких подполей, каждое из которых может быть одного из восьми предопределенных типов. В этих подполях можно указывать точный маршрут прохождения маршрутизаторов, регистрировать проходимые пакетом маршрутизаторы, помещать данные системы безопасности, а также временные отметки. Так как число подполей может быть произвольным, то в конце поля Резерв должно быть добавлено несколько байт для выравнивания заголовка пакета по 32-битной границе.
Максимальная длина поля данных пакета ограничена разрядностью поля, определяющего эту величину, и составляет 65535 байтов, однако при передаче по сетям различного типа длина пакета выбирается с учетом максимальной длины пакета протокола нижнего уровня, несущего IP-пакеты. Если это кадры Ethernet, то выбираются пакеты с максимальной длиной в 1500 байтов, умещающиеся в поле данных кадра Ethernet.
Рассмотрим более подробно, что такое фрагментация.
1.2.3 Фрагментация дейтаграмм
Различные среды передачи имеют различный максимальный размер передаваемого блока данных (MTU - Media Transmission Unit), это число зависит от скоростных характеристик среды и вероятности возникновения ошибки при передаче. Например, размер MTU в 10Мбит/с Ethernet равен 1536 октетам, в 100 Мбит/с FDDI - 4096 октетам.
При передаче дейтаграммы из среды с большим MTU в среду c меньшим MTU может возникнуть необходимость во фрагментации дейтаграммы. Фрагментация и сборка дейтаграмм осуществляются модулем протокола IP. Для этого применяются поля “ID” (Identification), “Flags” и “Fragment Offset” заголовка дейтаграммы.
Максимальное количество фрагментов равно 213=8192 при минимальном (8 октетов) размере каждого фрагмента. При большем размере фрагмента максимальное количество фрагментов соответственно уменьшается.
Сборка фрагментов осуществляется только в узле назначения дейтаграммы, поскольку разные фрагменты могут следовать в пункт назначения по разным маршрутам.
Если фрагменты задерживаются или утрачены при передаче, то у остальных фрагментов, уже полученных в точке сборки, TTL уменьшается на единицу в секунду до тех пор, пока не прибудут недостающие фрагменты. Если TTL становится равным нулю, то все фрагменты уничтожаются и ресурсы, задействованные на сборку дейтаграммы, высвобождаются.
Максимальное количество идентификаторов дейтаграмм - 65536. Если использованы все идентификаторы, нужно ждать до истечения TTL, чтобы можно было вновь использовать тот же самый ID, поскольку за TTL секунд “старая” дейтаграмма будет либо доставлена и собрана, либо уничтожена.
Передача дейтаграмм с фрагментацией имеет определенные недостатки. Например, как следует из предыдущего абзаца, максимальная скорость такой передачи равна 65536/TTL дейтаграмм в секунду. Если учесть, что рекомендованная величина TTL равна 120, получаем максимальную скорость в 546 дейтаграмм в секунду. В среде FDDI MTU равен примерно 4100 октетам, откуда получаем максимальную скорость передачи данных в среде FDDI не более 18 Мбит/с, что существенно ниже возможностей этой среды.
Другим недостатком фрагментации является низкая эффективность: при потере одного фрагмента заново передается вся дейтаграмма; при одновременном ожидании отставших фрагментов нескольких дейтаграмм создается ощутимый дефицит ресурсов и замедляется работа узла сети.
Способом обойти процесс фрагментации является применение алгоритма “Path MTU Discovery” (“Выявление MTU на пути следования”), этот алгоритм поддерживается протоколом TCP. Задачей алгоритма является обнаружение минимального MTU на всем пути от отправителя к месту назначения. Для этого посылаются дейтаграммы с установленным битом DF (“фрагментация запрещена”). Если они не доходят до места назначения, размер дейтаграммы уменьшается, и так происходит до тех пор, пока передача не будет успешной. После этого при передаче полезных данных создаются дейтаграммы с размером, соответствующим обнаруженному минимальному MTU.
Перейдём к рассмотрению того, как осуществляется адресация в протоколе IP.
1.2.4 Адрес протокола IP
IP-адрес является уникальным 32-битным идентификатором IP-интерфейса в Интернет. Часто говорят, что IP-адрес присваивается узлу сети (например, хосту); это верно в случае, если узел является хостом с одним IP-интерфейсом, иначе следует уточнить, об адресе какого именно интерфейса данного узла идет речь.
IP-адреса принято записывать разбивкой всего адреса по октетам (четыре), каждый октет записывается в виде десятичного числа, числа разделяются точками. Например, адрес
11000000101010000001000011110000
записывается как
11000000.10101000.00010000.11110000 = 192.168.16.240.
IP-адрес хоста состоит из номера IP-сети, который занимает старшую область адреса, и номера хоста в этой сети, который занимает младшую часть. Положение границы сетевой и хостовой частей (обычно оно характеризуется количеством бит, отведенных на номер сети) может быть различным, определяя различные типы IP-адресов.
1.2.5 Классы IP адресов
В классовой модели IP-адрес может принадлежать к одному из четырех классов сетей. Каждый класс характеризуется определенным размером сетевой части адреса, кратным восьми; таким образом, граница между сетевой и хостовой частями IP-адреса в классовой модели всегда проходит по границе октета. Принадлежность к тому или иному классу определяется по старшим битам адреса см. рис. 2.

Рис. 2
Класс А. Старший бит адреса равен нулю. Размер сетевой части равен 8 битам. Таким образом, может существовать всего примерно 27 сетей класса А, но каждая сеть обладает адресным пространством на 224 хостов. Так как старший бит адреса нулевой, то все IP-адреса этого класса имеют значение старшего октета в диапазоне 0 — 127, который является также и номером сети.
Класс В. Два старших бита адреса равны 10. Размер сетевой части равен 16 битам. Таким образом, может существовать всего примерно 214 сетей класса В, каждая сеть обладает адресным пространством на 216 хостов. Значения старшего октета IP-адреса лежат в диапазоне 128 — 191, при этом номером сети являются два старших октета.
Класс С. Три старших бита адреса равны 110. Размер сетевой части равен 24 битам. Количество сетей класса С примерно 221, адресное пространство каждой сети рассчитано на 254 хоста. Значения старшего октета IP-адреса лежат в диапазоне 192 - 223, а номером сети являются три старших октета.
Класс D. Сети со значениями старшего октета IP-адреса 224 и выше. Зарезервированы для специальных целей. Некоторые адреса используются для мультикастинга - передачи дейтаграмм группе узлов сети, например:
224.0.0.1 - всем хостам данной сети;
224.0.0.2 - всем маршрутизаторам данной сети.
В классе А выделены две особые сети, их номера 0 и 127. Сеть 0 используется при маршрутизации как указание на маршрут по умолчанию.
IP-интерфейс с адресом в сети 127 используется для адресации узлом себя самого (loop back, интерфейс обратной связи). Интерфейс обратной связи не обязательно имеет адрес в сети 127 (особенно у маршрутизаторов), но если узел имеет IP-интерфейс с адресом 127.0.0.1, то это - интерфейс обратной связи. Обращение по адресу loopback-интерфейса означает связь с самим собой (без выхода пакетов данных на уровень доступа к среде передачи); для протоколов на уровнях транспортном и выше такое соединение неотличимо от соединения с удаленным узлом, что удобно использовать, например, для тестирования сетевого программного обеспечения.
1.2.6 Зарезервированные IP адреса
В адресной схеме протокола выделяют особые IP-адреса:
|
IP адрес |
Назначение |
|
|
сетевые биты |
хостовые биты |
|
|
равны 0 |
равны 0 |
само передающее устройство |
|
номер сети |
равны 0 |
текущая IP сеть |
|
равны 0 |
номер хоста |
хост в данной сети |
|
равны 1 |
равны 1 |
все хосты в данной IP сети |
|
номер сети |
равны 1 |
все хосты в указанной IP сети |
|
127 |
любые |
адрес обратной связи (loop back) |
Если биты всех октетов адреса равны нулю, то он обозначает адрес того узла, который сгенерировал данный пакет. Это используется в ограниченных случаях, например в некоторых сообщениях протокола IP.
Если биты сетевого префикса равны нулю, полагается, что узел назначения принадлежит той же сети, что и источник пакета.
Когда биты всех октетов адреса назначения равны двоичной единице, пакет доставляется всем узлам, принадлежащим той же сети, что и отправитель пакета. Такая рассылка называется ограниченным широковещанием.
Наконец, если в битах адреса, соответствующих узлу назначения, стоят единицы, то такой пакет рассылается всем узлам указанной сети. Это называется широковещанием.
Специальное значение имеет, так же, адреса сети 127/8. Они используются для тестирования программ и взаимодействия процессов в пределах одной машины (как правило, для тестирования корректной работы стека TCP/IP). Пакеты, отправленные на этот интерфейс, обрабатываются локально, как входящие. Потому адреса из этой сети нельзя присваивать физическим сетевым интерфейсам.
1.2.7 Эффективное использование адресного пространства протокола IP
Несколько лет назад специалисты, занимающиеся Интернет, были в ужасе от лавинообразного роста числа пользователей этой всемирной "сети сетей". Их беспокоило, что 32-разрядное адресное пространство протокола Интернет (IP), на котором построена вся сеть, при таких темпах роста должно было бы переполниться уже через два-три года, оставив миллионы потенциальных пользователей "на обочине информационного шоссе".
Было придумано несколько решений этой проблемы.
1. Введение масок подсетей переменной длины (VLSM). Очень редко в локальную вычислительную сеть входит более 100-200 узлов: даже если взять сеть с большим количеством узлов, многие сетевые среды накладывают ограничения, например, в 1024 узла. Исходя из этого, целесообразность использования сетей класса А и В весьма сомнительна. Да и использование класса С для сетей, состоящих из 20-30 узлов, тоже является расточительством. Для решения этих проблем в двухуровневую иерархию IP-адресов (сеть -- узел) была введена новая составляющая -- подсеть. Идея заключается в "заимствовании" нескольких битов из узловой части адреса для определения подсети. Общая схема разбиения сети на подсети с масками переменной длины такова: сеть делится на подсети максимально необходимого размера. Затем некоторые подсети делятся на более мелкие, и рекурсивно далее, до тех пор, пока это необходимо. Об этом более подробно поговорим чуть позже.
2. Использование «приватных» (fake) сетей. Представим себе, что для работы некоторого отдела необходима организация локальной компьютерной сети с выделенным сервером, способным предоставить пользователям этой локальной сети файловый сервис и сервисы, составляющие основу интранет-технологий: электронная почта и телеконференции, WWW-сервис для доступа к базам данных. С другой стороны пользователи должны иметь со своих рабочих мест выход в Интернет для поиска необходимой им для работы информации. Обычная схема построения таких сетей состоит в получении на организацию диапазона реальных IP-адресов для рабочих станций и сервера и подключении к провайдеру услуг Интернет. При этом пользователи локальной сети получают выход через провайдера в Интернет, а сервер становится одним из ее ресурсов и доступен с любого компьютера, подключенного к Интернет. На первый взгляд такое решение приемлемо во всех случаях, но на самом деле это далеко не так. Например, если данные, хранящиеся на локальном сервере представляют некоторую важность, не допускающую их просмотра, изменения или уничтожения, то возникает проблема защиты этой информации от хакеров, населяющих Интернет наравне с нормальными пользователями. Как же в этом случае поступить? Оказалось, что решение есть и оно достаточно простое. Необходимо организовать шлюз, работающий по особым правилам, соединяющий локальную сеть и Интернет. Правила шлюза должны работать таким образом, что должны допускаться только те соединения, которые инициированы пользователями локальной сети. Все попытки соединиться с сервером или любой рабочей станцией локальной сети со стороны Интернет должны шлюзом отвергаться. Именно таким образом устроена и работает "приватная сеть". Ее основу составляет обычная локальная компьютерная сеть. Для соединения с Интернет используется специальный шлюз, построенный на специальном аппаратно-программном комплексе и способный обрабатывать проходящий через него трафик по правилам "запрещения/разрешения".Рабочие станции внутри приватной сети получают специальные адреса – fake-адреса. Так, если организована приватная сеть класса А, то адреса внутри сети: 10.0.0.1 – 10.255.255.255, если класса B, то 172.16.0.1 – 172.31.255.255, класса С – 192.168.0.1 – 192.168.0.0.
3. Использование динамического распределения адресов (DHCP, BootP). В больших сетях некоторые рабочие станции могут не иметь системного диска, а операционная система и сетевое программное обеспечение загружается через сеть. Для этого рабочая станция должна иметь стартовую программу, записанную в ПЗУ. Такое постоянное запоминающее устройство часто производится на фирме, изготовившей эту рабочую станцию, и по этой причине не содержат информации ни об адресе сервера, ни даже о своем IP-адресе. Мощным средством для загрузки бездисковых станций является протокол BOOTP (Bootstrap протокол, RFC-951, -1048, -1532). BOOTP пригоден и для загрузки бездисковых маршрутизаторов. Bootp осуществляет загрузку в два этапа. На первом этапе bootp лишь снабжает клиента информацией, где лежит нужные ему данные. Далее ЭВМ-клиент использует протокол RFTP для получения искомого загружаемого файла. Появление протокола Dynamic Host Configuration Protocol (DHCP) заметно упростило жизнь сетевых администраторов. Если раньше IP-адреса приходилось задавать вручную (хорошо еще, если с центральной консоли), то теперь эта процедура выполняется автоматически. Протокол DHCP был предложен в 1993 г., его развитием занимается специальная рабочая группа (DHC WG), входящая в состав IETF. DHCP появился не на пустом месте - различные схемы управления IP-адресами в сетевой среде предлагались и раньше. Однако эти схемы имеют по крайней мере один из двух недостатков - не допускают динамического назначения IP-адресов либо позволяют передавать от сервера на станцию-клиент лишь небольшое число параметров конфигурации. Сравнивая протоколы BOOTP и DHCP, нельзя не отметить появления в DHCP новых услуг. Во-первых, в этом протоколе предусмотрен механизм автоматической выдачи IP-адресов во временное пользование с возможностью их последующего присвоения новым клиентам. Во-вторых, клиент может получить от сервера все параметры конфигурации, которые ему необходимы для успешного функционирования в IP-сети.
4. Введение 6-й версии протокола IP. Создатели Интернета (а точнее, его предка - сети Arpanet) даже и не подозревали, какой успех ждет их детище. Поэтому не удивительно, что когда глобальная сеть начала семимильными шагами распространяться по всей планете, появились некоторые проблемы. Точнее, даже, не сами проблемы, а всего лишь предположения об их возникновении в ближайшем будущем. И самой серьезной из них являлось адресное пространство. В версии протокола IP (IPv4), длина IP адреса составляет 32 бита. То есть всего возможно около 4 миллиардов 300 миллионов вариантов. Сегодня этого пока достаточно, но уже совсем скоро может сложиться ситуация, когда IP-адресов не будет хватать на всех желающих. Решением проблемы стал протокол IPv6. У него достаточно много существенных отличий от своего предшественника. И главным из них, конечно же, является система адресации. В протоколе IPv6 длина IP-адресов расширяется с 32 до 128 бит. Таким образом, число их возможных вариантов вырастает до 3,4*101038. То есть, фактически, этих адресов в обозримом будущем будет более чем достаточно. Помимо этого, увеличение длины IP-адреса позволяет использовать больше уровней иерархии в системе адресации и ввести несколько различных типов адресов. Кроме этого, в протоколе IPv6 базовый заголовок пакетов оптимизирован для максимально быстрой его обработки. Это сделано для разгрузки маршрутизаторов и увеличения, таким образом, их пропускной способности. Также изменению подвергся механизм фрагментации, удалено широковещание и добавлена возможность использования криптографического алгоритма для защиты передаваемой информации.
1.2.8 Подсети. Маска подсети
Причины разбиения сети на подсети кроются в ранних спецификациях IP, где существовало только несколько сетей класса A, в которых можно было разместить несколько миллионов хостов.
Соединение такого количества сайтов в одну сеть влечет за собой огромный трафик и проблемы администрирования: управление таким количеством машин превратится в кошмар, а сеть замрет под грузом собственного трафика.
Введем подсети: сетевой адрес класса A может быть поделен так, чтобы распределить его на несколько (если не больше) отдельных сетей. Управление каждой отдельной сетью можно легко делегировать.
Другие причины создания подсетей:
· Физическая организация сайта может создавать ограничения (длина кабеля) на соединения в физической инфраструктуре, требуя создания нескольких сетей. Разбивка на подсети позволяет решить эту задачу в пределах IP окружения используя единственный IP адрес сети. В действительности этот метод широко используется ISP, которые хотят раздать своим подключенным по постоянным каналам клиентам статические IP адреса.
· Сетевой трафик слишком высок, что приводит к снижению производительности сети. Разбивкой сети на подсети трафик, относящийся к данному сетевому сегменту, может оставаться в локальных рамках - это обеспечивает сокращение общего трафика и повышение скорости сети без действительного расширения полосы пропускания сети;
· Требования безопасности могут заставлять разбивать пользователей на отдельные классы, которые не должны находиться в одной сети, так как трафик в сети может быть всегда перехвачен знающим пользователем. Разбивка на подсети позволяет предотвратить подглядывание трафика лицами из других подразделений компании.
А) Двухуровневая иерархия
Для обеспечения гибкости в назначении адресов компьютерным сетям разработчики определили, что адресное пространство протокола IP должно быть разделено на три основных класса - A, B и C. Каждый из этих основных классов фиксирует границу между сетевым префиксом и номером хоста в разных точках 32-разрядного адреса. Одно из основных достоинств использования классов в том, что каждый адрес содержит ключ для идентификации границы между сетевым префиксом и номером хоста. Например, если старшие два бита адреса равны "10", то точка раздела находится между 15 и 16 битом. Недостатком такого метода является необходимость изменения адреса сети при превышении в сетях класса С числа устройств в 255, например на адреса класса B. Изменение сетевых адресов может отнять много времени и усилий у администратора по отладке сети. Также очевидная проблема заключается в большой вероятности неэффективного использования предоставленного кому-либо пула адресов(напр. В сетях класса А).
Б) Трехуровневая иерархия
В 1985 году документом RFC 950 определен стандартный процесс поддержки формирования подсетей или разделения единственного номера сети классов А, B и C на меньшие части. Формирование подсетей было введено для разрешения следующих проблем:
1. разбухания таблиц маршрутизации в маршрутизаторов Интернет;
2. дефицита номеров сетей при необходимости расширения их числа.
Обе эти проблемы решались за счет добавления еще одного уровня иерархии к адресной структуре протокола IP. Вместо двухуровневой иерархии концепция формирования подсетей вводит поддержку трехуровневой иерархии.
Расширенный сетевой префикс состоит из префикса сети и номера подсети. Расширенный сетевой префикс можно идентифицировать с помощью маски подсети (subnet mask). Маска подсети - это число, двоичная запись которого содержит единицы в разрядах, интерпретируемых как номер сети. Маска подсети позволяет провести четкую границу между двумя частями IP-адреса. Одна часть идентифицирует номер подсети, вторая - предназначается для идентификации хостов в этой подсети.
Хосты и маршрутизаторы используют старшие биты IP-адреса для определения его класса. После того как класс определен, хост может легко найти границу между битами номера сети и номера хоста в этой сети. Однако класс адреса ничем не может помочь в определении номера подсети. Для решения данного вопроса служит 32-разрядная маска подсети, позволяющая однозначно определить требуемую границу. Для стандартных классов сетей маски имеют следующие значения:
· 255.0.0.0 - маска для сети класса А;
· 255.255.0.0 - маска для сети класса B;
· 255.255.255.0 - маска для сети класса C.
Другой способ записи маски подсети:
Через «/» после IP адреса записывается количество единиц в маске (например: 192.168.1.0/24)
· 255.0.0.0 = /8
· 255.255.0.0 = /16
· 255.255.255.0 = /24
На следующем рисунке (рис. 4) мы видим, как сокращается таблица маршрутизации при использовании технологии VLSM: маршрутизатору B ничего не надо знать о подсетях, находящимися с левой стороны, и всего одна запись в его таблице маршрутизации идентифицирует все рабочие станции, находящихся за маршрутизатором А.

Рис. 4
При разделении сети на подсети полезно помнить некоторые правила:
·
Количество хостов в подсети считается по формуле: ![]() где n
– количество битов, кодирующих в адресе номер хоста (-2 учитывает адрес сети и
широковещательный адрес!).
где n
– количество битов, кодирующих в адресе номер хоста (-2 учитывает адрес сети и
широковещательный адрес!).
·
Количество подсетей считается по формуле: ![]() где n –
количество битов, кодирующих в адресе подсеть (аккуратнее! Для протоколов
маршрутизации не поддерживающих VLSM (RIP v.1 и т.д.) нельзя использовать
нулевую и последнюю подсети).
где n –
количество битов, кодирующих в адресе подсеть (аккуратнее! Для протоколов
маршрутизации не поддерживающих VLSM (RIP v.1 и т.д.) нельзя использовать
нулевую и последнюю подсети).
· Все подсети после первой, кратны ей по последнему октету (байту).
Пример разделения сети 193.1.1.0/24 на 8 подсетей по 30 хостов в каждой:
|
Сеть/адрес |
Точечно-десятичный формат |
Двоичный формат |
|
Базовая сеть |
193.1.1.0/24 |
00000001.00000000 |
|
Подсеть №0 |
193.1.1.0/27 |
00000001.00000000 |
|
Подсеть №1 |
193.1.1.32/27 |
00000001.00100000 |
|
Подсеть №2 |
193.1.1.64/27 |
00000001.01000000 |
|
Подсеть №3 |
193.1.1.96/27 |
00000001.01100000 |
|
Подсеть №4 |
193.1.1.128/27 |
00000001.10000000 |
|
Подсеть №5 |
193.1.1.160/27 |
00000001.10100000 |
|
Подсеть №6 |
193.1.1.192/27 |
00000001.11000000 |
|
Подсеть №7 |
193.1.1.224/27 |
00000001.11100000 |
Очень часто, при реализации проектов локальных сетей, приходится сталкиваться с задачами разделения выделенного адресного пространства с максимальной эффективностью. Весьма полезно в таких случаях использовать технологию VLSM. Пример типичной задачи на эффективное разделение сети на подсети представлен на рис. 6.

Рис. 6
В данном случае следует действовать по следующему алгоритму: cначала считается количество бит (а значит, и маска подсети), необходимое для кодирования достаточного количества хостов в каждой подсети (3 подсети по 2 хоста – маска /30, 2 подсети по 12 хостов – маска /28, 1 подсеть содержащая 28 хостов – маска /27 и 1 подсеть содержащая 60 хостов – маска /26. Затем – адреса подсетей, а потом уже первый и последний адреса в подсети. Причем начинать расчет следует с подсетей с наименьшим количеством хостов и заканчивать расчет подсетями с наибольшим количеством хостов. Пример решения данной задачи представлен на рис. 7 (первый и последний в подсети адреса на рисунке представлены без префикса 192.168.).

Рис. 7
1.2.9 Организации, управляющие распределением IP адресов
Очевидно, что распределение IP адресов между пользователями должно регулироваться. Для этого существуют несколько организаций, которые решают этот вопрос, выделяют IP адреса тому или иному провайдеру. Рассмотрим, какие организации «проходит» IP адрес, чтобы попасть в личное ваше пользование.
· IANA – The Internet Assigned Numbers Authority (Управление назначением адресов в Интернет) - организация, осуществляющая контроль за распределением всего пространства Интернет адресов, включая IP-адреса. IANA выделяет адресное пространство Региональным регистратурам в соответствии с их потребностями.
· RIR – Regional Internet Registry (Региональная регистратура Интернет) - организация, занимающаяся распределением адресного пространства в пределах одного из 5-х регионов (Северная Америка, Латинская Америка, Европа, Азия, Африка) см. рис. 8. Региональные регистратуры осуществляют координацию деятельности Локальных регистратур. Северная Америка - поддерживается ARIN (American Registry for Internet Numbers). Латинская Америка и Караибские острова - поддерживается LACNIC (Regional Latin-American and Caribbean IP Address Registry). Европа ближний восток, центральная Азия, Африка до экватора - база данных поддерживается RIPE Network Coordination Centre (RIPE NCC). Азия и Тихоокеанский регион - поддерживается APNIC (Asia Pacific Network Information Centre). Ну и, наконец, Африка – поддерживается AfriNIC (African Network Information Centre).
·
LIR – Local Internet Registries (Локальная
регистратура Интернет) - организация, занимающаяся распределением адресного
пространства пользователям сетей (сервис-провайдерам и их абонентам) и
оказанием сопутствующих регистрационных услуг. Как правило, Локальными
регистратурами управляют крупные сервис-провайдеры и корпоративные сети.
LIR'ы делятся на: а) Extra large; б) Large; в) Medium; г) Small; д) Extra small.
Самая большая (Extra large) российская LIR - РосНИИРОС (Российский НИИ Развития
Общественных Сетей)
· ISP - Internet Service Provider (сервис-провайдер Интернет) - поставщик услуг Интернет.
· End-user (конечный пользователь) - организация, которая использует выделенное ей адресное пространство для работы своих сетей и подключенная к сети Интернет.
1.2.10 Протокол ARP
Протокол ARP (Address Resolution Protocol, Протокол распознавания адреса) предназначен для преобразования IP-адресов в MAC-адреса, часто называемые также физическими адресами.
Поиск по данному IP-адресу соответствующего Ethernet-адреса производится протоколом ARP, функционирующим на уровне доступа к среде передачи. Протокол поддерживает в оперативной памяти динамическую arp-таблицу в целях кэширования полученной информации. Порядок функционирования протокола следующий.
С межсетевого уровня поступает IP-дейтаграмма для передачи в физический канал (Ethernet), вместе с дейтаграммой передается, среди прочих параметров, IP-адрес узла назначения. Если в arp-таблице не содержится записи об Ethernet-адресе, соответствующем нужному IP-адресу, модуль arp ставит дейтаграмму в очередь и формирует широковещательный запрос. Запрос получают все узлы, подключенные к данной сети; узел, опознавший свой IP-адрес, отправляет arp-ответ (arp-response) со значением своего адреса Ethernet (см. рис.9). Полученные данные заносятся в таблицу, ждущая дейтаграмма извлекается из очереди и передается на инкапсуляцию в кадр Ethernet для последующей отправки по физическому каналу. Протокол ARP может поддерживать не только Ethernet, но и другие типы физических сред.

Рис. 9
Следует отметить что события будут развиваться по вышеописанному сценарию в том случае если IP адрес получающей стороны находится в той же подсети что и IP адрес стороны, посылающей данные. В противном случае, передача пакета в другую IP подсеть осуществляется посредством маршрутизатора.
1.2.11 Работа протокола ARP совместно с протоколом IP
Дейтаграмма, направленная во внешнюю (в другую) подсеть, должна быть передана маршрутизатору. Предположим, хост А отправляет дейтаграмму хосту В через маршрутизатор G. Несмотря на то, что в заголовке дейтаграммы, отправляемой из А, в поле “Destination” указан IP-адрес В, кадр Ethernet, содержащий эту дейтаграмму, должен быть доставлен маршрутизатору. Это достигается тем, что IP-модуль при вызове ARP-модуля передает тому вместе с дейтаграммой в качестве IP-адреса узла назначения адрес маршрутизатора, извлеченный из таблицы маршрутов. Таким образом, дейтаграмма с адресом В инкапсулируется в кадр с MAC-адресом G (см. рис.10а). Модуль Ethernet на маршрутизаторе G получает из сети этот кадр, так как кадр адресован ему, извлекает из кадра данные (то есть дейтаграмму) и отправляет их для обработки модулю IP. Модуль IP обнаруживает, что дейтаграмма адресована не ему, а хосту В, и по своей таблице маршрутов определяет, куда ее следует переслать. Далее дейтаграмма опять опускается на нижний уровень, к соответствующему физическому интерфейсу, которому передается в качестве IP-адреса узла назначения адрес следующего маршрутизатора, извлеченный из таблицы маршрутов, или сразу адрес хоста В, если маршрутизатор G может доставить дейтаграмму непосредственно к нему (см. рис.10б).

Рис. 10а

Рис. 10б
1.3 Технология VLAN. Протокол STP
1.3.1 Введение
Коммутация в локальных сетях (ЛВС) является одной из основ происходящего сегодня перехода к использованию технологий следующего поколения. Традиционные ЛВС рассчитаны на совместное использование ресурсов пользователями небольшого числа станций (обычно до 50). К числу разделяемых ресурсов относятся файлы и периферийные устройства (принтеры, модемы и т.п.). Поскольку картина трафика в таких сетях имеет ярко выраженный взрывной характер, использование разделяемой между всеми пользователями полосы может приводить к существенному замедлению работы. Стандарты Ethernet и token ring регулируют доступ сетевых устройств к разделяемой среде передачи. Когда одно из устройств передает данные в сеть, все остальные должны ждать окончания передачи, не делая попыток передать в сеть свои данные.
Такая схема разделения доступа к среде очень эффективна в небольших сетях, используемых для совместного использования файлов или принтеров. Сегодня размер и сложность локальных сетей значительно возросли, а число устройств измеряется тысячами. В сочетании с ростом потребностей пользователей недетерминистический характер традиционных сетевых архитектур (таких как Ethernet и token ring) начал ограничивать возможности сетевых приложений. Коммутация ЛВС является популярной технологией, способной продлить жизнь существующих ЛВС на базе Ethernet и token ring. Преимущества коммутации заключаются в сегментировании сетей - делении их на более мелкие фрагменты со значительным снижением числа станций в каждом сегменте. Изоляция трафика в небольшом сегменте приводит к многократному расширению доступной каждому пользователю полосы, а поддержка виртуальных ЛВС (VLAN) значительно повышает гибкость системы.
Коммутационные устройства относятся ко второму (канальному) уровню модели OSI. Среди них можно выделить следующие:
• Концентратор (hub) – просто повторяет полученный кадр на всех своих портах, кроме того, из которого этот кадр пришел.
• Коммутатор (switch) - считывает MAC адрес источника входящего фрейма и сохраняет эту информацию в таблице коммутации. Эта таблица содержит MAC адреса и номера портов, связанных с ними. Далее, коммутатор проверяет MAC адрес назначения фрейма и немедленно смотрит в таблицу коммутации. Если коммутатор нашел соответствующий адрес, он копирует фрейм только в этот порт. Если он не может найти адрес, он копирует фрейм во все порты.
• Мост (bridge). Разница между мостом и коммутатором состоит в том, что мост в каждый момент времени может осуществлять передачу кадров только между одной парой портов, а коммутатор одновременно поддерживает потоки данных между всеми своими портами. Другими словами, мост передает кадры последовательно, а коммутатор параллельно. Следует отметить, что в последнее время локальные мосты полностью вытеснены коммутаторами. Мосты используются только для связи локальных сетей с глобальными, то есть как средства удаленного доступа, поскольку в этом случае необходимость в параллельной передаче между несколькими парами портов просто не возникает.
Ниже показан пример таблицы коммутации для коммутатора с поддержкой технологии VLAN. В первом поле каждой записи указан номер VLAN, к которой принадлежит MAC-адрес получателя, во втором поле непосредственно сам MAC-адрес, и в третьем поле указан номер порта, в который необходимо передать кадр в случае адресации его на тот или иной MAC-адрес.
|
VLAN |
Destination MAC |
Destination Ports or VCs |
|
1 |
00-60-2f-9d-a9-00 |
3 |
|
1 |
00-b0-2f-9d-b1-00 |
3 |
|
1 |
00-60-2f-86-ad-00 |
1 |
|
1 |
00-c0-0c-0a-bd-4b |
4 |
|
1 |
00-11-2f-cc-da-a6 |
6 |
Методы коммутации
В настоящее время, в аппаратуре вторго уровня OSI используются следующие методы коммутации.
Коммутация "на лету" (On-the-fly) или "сквозная пересылка" (Cut-through)
Во время коммутации "на лету" передача пакета в выходной порт начинается практически сразу после начала приема. Передача пакета в выходной порт начинается после получения заголовка пакета и прочтения МАС-адреса получателя, по которому определяется необходимый порт в соответствии с таблицей МАС-адресов. Таким образом, не тратится время на запись пакета в буфер, проверку контрольной суммы и размера пакета. К недостаткам таких коммутаторов, помимо отсутствия механизма определения ошибочных пакетов, относится невозможность поддержки интерфейсов, работающих с различными скоростями.
Коммутация с промежуточной буферизацией (Store-and-forward)
При использовании этого метода коммутатор должен принять пакет полностью, прежде чем он будет направлен в другой порт. Пакет записывается в буфер коммутатора. Вычисляется контрольная сумма для принятых пакетов, и при обнаружении несоответствия значений пакет отбрасывается как ошибочный. Кроме того, отбрасываются пакеты некорректных размеров (меньше 64 байтов и больше 1518 байтов). Заметим также, что этот метод позволяет создавать коммутаторы, интерфейсы которых могут работать с различными скоростями (например, 10 и 100 Мбит/с).
Бесфрагментная коммутация (Fragment-Free)
Этот метод является улучшенным вариантом коммутации "на лету". Основное отличие заключается в том, что при бесфрагментной коммутации передача пакета на выходной порт начинается лишь после приема первых 64 байтов пакета. В результате анализа этих 64 байтов можно обнаружить большинство ошибочных пакетов. Коммутаторы такого типа также не позволяют использовать в одном устройстве интерфейсы, работающие с различными скоростями.
Гибридная коммутация (Hybrid)
Некоторые коммутаторы способны поддерживать два или три метода коммутации. Для определения метода применительно к отдельно взятому пакету используются различные алгоритмы. Коммутаторы этого типа позволяют воспользоваться преимуществами любого из перечисленных методов.
1.3.2 Преимущества коммутации
Сегментирование сетей - деление их на более мелкие фрагменты со значительным снижением числа станций в каждом сегменте. Коммутаторы ЛВС сегментируют сеть - делят ее на меньшие сегменты, которые в свою очередь являются коллизионными доменами (collision domains) – частями сети, в которых происходит конкурентная борьба рабочих станций за среду передачи и соответственно возникают коллизии, а затем соединяют эти сегменты, давая им возможность связаться друг с другом. Путем сокращения числа узлов в сегменте сегментация сокращает число коллизий и увеличивает доступную пропускную способность в расчете на один узел. А путем соединения сегментов через коммутаторы формируется единая ЛВС с потенциальной пропускной способностью, во много раз превышающей пропускную способность первоначальной односегментной ЛВС. В настоящее время, как правило применяется микросегментация – метод, при котором с каждым порт коммутатора соединен не сегмент сети, а одна рабочая станция. Это позволяет использовать всю возможную пропускную способность сети, без конкуренции с другими рабочими станциями.
Также, использование коммутаторов дает возможность фильтрации кадров и использования различных классов обслуживания (потоки с более высоким классом обслуживания получают приоритет перед остальными).
1.3.3 Назначение и преимущества использования протокола STP
Основное предназначение STP (Spanning Tree Protocol)— удаление петель в топологии сети и автоматическое управление топологией сети с дублирующими каналами. Действительно, если сетевое оборудование связано для надежности избыточным числом соединений, то без принятия дополнительных мер, кадры будут доставляться получателю в нескольких экземплярах, что приведет к сбоям и возникновению широковещательных штормов (broadcast storm) в случае отправки широковещательных кадров. Следовательно, в каждый момент времени должен быть задействован только один из параллельных каналов, но при этом необходимо иметь возможность переключения при отказах или физическом изменении топологии. С этой задачей может вручную справиться администратор, однако более элегантным и экономичным решением, освобождающим от необходимости круглосуточного мониторинга состояния системы человеком, является использование STP.
Для своей работы STP строит граф, называемый также «деревом», создание которого начинается с корня (root). Корнем становится одно из STP-совместимых устройств, выигравшее выборы. Каждое STP-совместимое устройство (это может быть коммутатор, маршрутизатор или другое оборудование, но для простоты далее мы будем называть такое устройство мостом) при включении считает, что оно является корнем. При этом оно периодически посылает на все свои порты специальные блоки данных — Bridge Protocol Data Units (BPDU). Адрес получателя в пакетах, несущих BPDU, является групповым, что обеспечивает его пропуск неинтеллектуальным оборудованием.
В данном случае под адресом понимается MAC-адрес, так как протокол STP функционирует на уровне управления доступом к среде передачи (Media Access Control, MAC). Из этого также следует, что все дальнейшие рассуждения о STP и его уязвимостях не привязаны к какому-то одному методу передачи, т. е. в равной мере относятся к Ethernet, Token Ring и т. д.
Получив очередной BPDU от другого устройства, мост сравнивает полученные параметры со своими и, в зависимости от результата, перестает или продолжает оспаривать статус корня. В результате корнем становится устройство c наименьшим значением идентификатора моста (Bridge ID). Последний представляет собой комбинацию MAC-адреса и заданного для моста приоритета. Очевидно, что в сети с единственным STP-совместимым устройством оно и будет корнем.
Выбранный корень, или назначенный корневой мост (Designated Root Bridge, в соответствии с терминологией стандарта), не несет никакой дополнительной нагрузки — он всего лишь служит отправной точкой для построения топологии.
Для всех остальных мостов в сети определяется корневой порт (Root Port), т. е. ближайший к корневому мосту порт. От других портов, соединенных с корневым мостом непосредственно или через другие мосты, он отличается своим идентификатором — комбинации из его номера и задаваемым администратором «веса».
На процесс выборов влияет и стоимость пути до корня (Root Path Cost) — она складывается из стоимости пути до корневого порта данного моста и стоимости путей до корневых портов мостов по всему маршруту до корневого моста. Эта стоимость может определяться временем передачи по линку, а также стоимостью портов, через которые происходит передача. Стоимость портов может задаваться вручную администратором.
Помимо выделенного корневого моста в STP вводится логическое понятие назначенного моста (Designated Bridge) — владелец этого статуса считается главным в обслуживании данного сегмента локальной сети. Статус назначенного моста также выборный и может переходить от одного устройства к другому.
Аналогичным образом вводится логическое понятие выборного назначенного порта (Designated Port, он обслуживает данный сегмент сети), а для него — понятие соответствующей стоимости пути (Designated Cost).
После окончания всех выборов наступает фаза стабильности, характеризуемая следующими условиями.
1. В сети только одно устройство считает себя корнем, а остальные периодически анонсируют его как корень.
2. Корневой мост регулярно посылает на все свои порты пакеты с BPDU. Интервал времени, через который происходит рассылка, называется интервалом приветствия (Hello Time).
3. В каждом сегменте сети имеется единственный назначенный порт, через который происходит обмен трафиком с корневым мостом. Он имеет наименьшее значение стоимости пути до корня по сравнению с другими портами в сегменте. При равенстве этой величины в качестве назначенного выбирается порт с наименьшим идентификатором порта (MAC-адрес порта и его приоритет).
4. BPDU принимаются и отправляются STP-совместимым устройством на всех его портах, даже на тех, которые были "отключены" в результате работы STP. Однако BPDU не принимаются на портах, которые были "отключены" администратором.
5. Каждый мост осуществляет пересылку (Forwarding) пакетов только между корневым портом и назначенными портами соответствующих сегментов. Все остальные находятся в блокированном состоянии (Blocking).
Как следует из последнего пункта, STP управляет топологией путем изменения состояния портов, которое может принимать следующие значения:
· блокирован (Blocking). Порт заблокирован, однако, в отличие от пользовательских кадров, кадры с пакетами STP (BPDU) принимаются и обрабатываются;
· ожидает (Listening). Первый этап подготовки к состоянию пересылки. В отличие от пользовательских кадров, кадры с пакетами STP (BPDU) принимаются и обрабатываются. Обучения не происходит, так как в этот период в таблицу коммутации может попасть недостоверная информация;
· обучается (Learning). Второй этап подготовки к состоянию пересылки. Кадры с пакетами STP (BPDU) принимаются и обрабатываются, а пользовательские кадры мост принимает для построения таблицы коммутации, но не пересылает данные;
· передает (Forwarding). Рабочее состояние портов, когда передаются как кадры с пакетами STP, так и кадры пользовательских протоколов.
· Отключен (Disabled). Порт не предпринимает никакой активности.
1.3.4 Основы технологий VLAN
Kроме своего основного назначения — повышения пропускной способности соединений в сети, коммутатор позволяет локализовать потоки информации, а также контролировать эти потоки и управлять ими с помощью механизма пользовательских фильтров. Однако пользовательский фильтр способен воспрепятствовать передаче кадров лишь по конкретным адресам, тогда как широковещательный трафик он передает всем сегментам сети. Таков принцип действия реализованного в коммутаторе алгоритма работы моста, поэтому сети, созданные на основе мостов и коммутаторов, иногда называют плоскими — из-за отсутствия барьеров на пути широковещательного трафика. Таким образом, мосты и коммутаторы делят коллизионные домены на части, с помощью сегментации, но при этом оставляют неизменным один общий широковещательный домен (broadcast domain - часть сети, в которой свободно распространяется широковещательный трафик).
Технология виртуальных локальных сетей (Virtual LAN, VLAN) позволяет преодолеть указанное ограничение. Виртуальной сетью называется группа узлов сети, трафик которой, в том числе и широковещательный, на канальном уровне полностью изолирован от других узлов (см. рис.). Это означает, что непосредственная передача кадров между разными виртуальными сетями невозможна, независимо от типа адреса — уникального, группового или широковещательного. В то же время внутри виртуальной сети кадры передаются в соответствии с технологией коммутации, т. е. только на тот порт, к которому приписан адрес назначения кадра.

Виртуальные сети могут пересекаться, если один или несколько компьютеров включено в состав более чем одной виртуальной сети. На рисунке сервер электронной почты входит в состав виртуальных сетей 3 и 4, и поэтому его кадры передаются коммутаторами всем компьютерам, входящим в эти сети. Если же какой-то компьютер отнесен только к виртуальной сети 3, то его кадры до сети 4 доходить не будут, но он может взаимодействовать с компьютерами сети 4 через общий почтовый сервер. Данная схема не полностью изолирует виртуальные сети друг от друга — так, инициированный сервером электронной почты широковещательный шторм захлестнет и сеть 3, и сеть 4.
1.3.5 Типы VLAN
Сети VLAN могут быть определены по:
· Порту (наиболее частое использование)
· MAC адресу (очень редко)
· Идентификатору пользователя User ID (очень редко)
· Сетевому адресу (редко в связи с ростом использования DHCP)
В данном пособии мы подробно рассмотрим наиболее часто используемый тип VLAN – VLAN определенные на основе портов. При использовании VLAN на основе портов каждый порт коммутатора назначается в определённую VLAN, независимо от того, какой пользователь или компьютер подключен к данному порту. Это означает, что все пользователи, подключенные к этому порту, будут членами одной VLAN. Создание виртуальных сетей на основе группирования портов не требует от администратора большого объема ручной работы – достаточно каждому порту, находящемуся в одной VLAN, присвоить один и тот же идентификатор VLAN (VLAN ID). При применении данной технологии VLAN, каждому порту должен быть присвоен тип: tagged порт или untagged порт. Untagged порты – принадлежат только одной VLAN и через них никогда не проходят кадры других VLAN. В свою очередь tagged порты – могут принадлежать к нескольким VLAN. Они используются для обмена информацией между коммутаторами. Для различения кадров одной VLAN от другой при прохождении через tagged порт в заголовок каждого кадра ставится специальная метка – tag. Кроме данных двух типов портов существует еще термин транковый (trunk) порт. Транковый порт – понятие неоднозначное. В формулировке компании Cisco - это по сути tagged порт или вообще порт используемый транковыми протоколами. В формулировке других компаний (например 3Com, Allied Telesyn, HP) – это порт повышенной пропускной способности, в том числе несколько портов, объединенных в один виртуальный в целях повышения его пропускной способности. На рисунке показан пример использования транкового порта в локальной сети.
![]()
Термин «транковые протоколы», включает в себя все протоколы, используемые для создания и поддержания VLAN на коммутаторах. Именно с помощью этих протоколов портам коммутатора назначаются типы tagged и untagged, а также расставляются tag метки в заголовках кадров.
Рассмотрим несколько транковых
протоколов подробнее. На сегодняшний день, наиболее распространенным и
используемым транковым протоколом является технология IEEE 802.1Q. В
виртуальных сетях, основанных на стандарте IEEE 802.1Q, информация о
принадлежности передаваемых Ethernet-кадров к той или иной виртуальной сети
встраивается в сам передаваемый кадр. Таким образом, стандарт IEEE 802.1Q
определяет изменения в структуре кадра Ethernet, позволяющие передавать
информацию о VLAN по сети.
К кадру Ethernet добавляется метка (Tag) длиной 4 байта - такие кадры называют
кадрами с метками (Tagged frame). Дополнительные биты содержат информацию по
принадлежности кадра Ethernet к виртуальной сети и о его приоритете (см. рис.).

Добавляемая метка кадра включает в себя двухбайтовое поле TPID (Tag Protocol Identifier) и двухбайтовое поле TCI (Tag Control Information). Поле TCI, в свою очередь, состоит из полей Priority, CFI и VID. Поле Priotity длиной 3 бита задает восемь возможных уровней приоритета кадра. Поле VID (VLAN ID) длиной 12 бит является идентификатором виртуальной сети. Эти 12 бит позволяют определить 4096 различных виртуальных сетей, однако идентификаторы 0 и 4095 зарезервированы для специального использования, поэтому всего в стандарте 802.1Q возможно определить 4094 виртуальные сети. Поле CFI (Canonical Format Indicator) длиной 1 бит зарезервировано для обозначения кадров сетей других типов (Token Ring, FDDI), передаваемых по магистрали Ethernet, и для кадров Ethernet всегда равно 0. Изменение формата кадра Ethernet приводит к тому, что сетевые устройства, не поддерживающие стандарт IEEE 802.1Q (такие устройства называют Tag-unaware), не могут работать с кадрами, в которые вставлены метки, а сегодня подавляющее большинство сетевых устройств (в частности, сетевые Ethernet-контроллеры конечных узлов сети) не поддерживают этот стандарт. Поэтому для обеспечения совместимости с устройствами, поддерживающими стандарт IEEE 802.1Q (Tag-aware-устройства), коммутаторы стандарта IEEE 802.1Q должны поддерживать как традиционные Ethernet-кадры, то есть кадры без меток (Untagged), так и кадры с метками (Tagged). Входящий и исходящий трафики, в зависимости от типа источника и получателя, могут быть образованы и кадрами типа Tagged, и кадрами типа Untagged - только в этом случае можно достигнуть совместимости с внешними по отношению к коммутатору устройствами. Трафик же внутри коммутатора всегда образуется пакетами типа Tagged. Поэтому для поддержки различных типов трафиков и для того, чтобы внутренний трафик коммутатора образовывался из пакетов Tagged, на принимаемом и передающем портах коммутатора кадры должны преобразовываться в соответствии с предопределенными правилами.
1.3.6 Правила входящего порта (Ingress rules)

Рассмотрим более подробно процесс передачи кадра через коммутатор (см. рис.). По отношению к трафику каждый порт коммутатора может быть как входным, так и выходным. После того как кадр принят входным портом коммутатора, решение о его дальнейшей обработке принимается на основании предопределенных правил входного порта (Ingress rules). Поскольку принимаемый кадр может относиться как к типу Tagged, так и к типу Untagged, то правилами входного порта определяется, какие типы кадров должны приниматься портом, а какие отфильтровываться. Возможны следующие варианты: прием только кадров типа Tagged, прием только кадров типа Untagged, прием кадров обоих типов. По умолчанию для всех коммутаторов правилами входного порта устанавливается возможность приема кадров обоих типов. Если правилами входного порта определено, что он может принимать кадр Tagged, в котором имеется информация о принадлежности к конкретной виртуальной сети (VID), то этот кадр передается без изменения. А если определена возможность работы с кадрами типа Untagged, в которых не содержится информации о принадлежности к виртуальной сети, то прежде всего такой кадр преобразуется входным портом коммутатора к типу Tagged (напомним, что внутри коммутатора все кадры должны иметь метки о принадлежности к виртуальной сети). Чтобы такое преобразование стало возможным, каждому порту коммутатора присваивается уникальный PVID (Port VLAN Identifier), определяющий принадлежность порта к конкретной виртуальной сети внутри коммутатора (по умолчанию все порты коммутатора имеют одинаковый идентификатор PVID=1). Кадр типа Untagged преобразуется к типу Tagged, для чего дополняется меткой VID (см. рис.). Значение поля VID входящего Untagged-кадра устанавливается равным значению PVID входящего порта, то есть все входящие Untagged-кадры автоматически приписываются к той виртуальной сети внутри коммутатора, к которой принадлежит входящий порт.

Правила продвижения пакетов (Forwarding Process)
После того как все входящие кадры отфильтрованы, преобразованы или оставлены без изменения в соответствии с правилами входящего порта, решение об их передаче к выходному порту основывается на предопределенных правилах продвижения пакетов. Правило продвижения пакетов внутри коммутатора заключается в том, что пакеты могут передаваться только между портами, ассоциированными с одной виртуальной сетью. Как уже отмечалось, каждому порту присваивается идентификатор PVID, который используется для преобразования принимаемых Untagged-кадров, а также для определения принадлежности порта к виртуальной сети внутри коммутатора с идентификатором VID=PVID. Таким образом, порты с одинаковыми идентификаторами внутри одного коммутатора ассоциируются с одной виртуальной сетью. Если виртуальная сеть строится на базе одного коммутатора, то идентификатора порта PVID, определяющего его принадлежность к виртуальной сети, вполне достаточно. Правда, создаваемые таким образом сети не могут перекрываться, поскольку каждому порту коммутатора соответствует только один идентификатор. В этом смысле создаваемые виртуальные сети не обладали бы такой гибкостью, как виртуальные сети на основе портов. Однако стандарт IEEE 802.1Q с самого начала задумывался для построения масштабируемой инфраструктуры виртуальных сетей, включающей множество коммутаторов, и в этом состоит его главное преимущество по сравнению с технологией образования VLAN на основе портов. Но для того, чтобы расширить сеть за пределы одного коммутатора, одних идентификаторов портов недостаточно, поэтому каждый порт может быть ассоциирован с несколькими виртуальными сетями, имеющими различные идентификаторы VID. Если адрес назначения пакета соответствует порту коммутатора, который принадлежит к той же виртуальной сети, что и сам пакет (могут совпадать VID пакета и VID порта или VID пакета и PVID порта), то такой пакет может быть передан. Если же передаваемый кадр принадлежит к виртуальной сети, с которой выходной порт никак не связан (VID пакета не соответствует PVID/VID порта), то кадр не может быть передан и отбрасывается.
Правила выходного порта (Egress rules)
После того как кадры внутри коммутатора переданы на выходной порт, их дальнейшее преобразование зависит от правил выходного порта. Как уже говорилось, трафик внутри коммутатора создается только пакетами типа Tagged, a входящий и исходящий трафики могут быть образованы пакетами обоих типов. Соответственно правилами выходного порта (правило контроля метки - Tag Control) определяется, следует ли преобразовывать кадры Tagged к формату Untagged. Каждый порт коммутатора может быть сконфигурирован как Tagged или Untagged Port. Если выходной порт определен как Tagged Port, то исходящий трафик будет создаваться кадрами типа Tagged с информацией о принадлежности к виртуальной сети. Следовательно, выходной порт не меняет тип кадров, оставляя их такими же, какими они были внутри коммутатора. К указанному порту может быть подсоединено только устройство, совместимое со стандартом IEEE 802.1Q, например коммутатор или сервер с сетевой картой, поддерживающей работу с виртуальными сетями данного стандарта. Если же выходной порт коммутатора определен как Untagged Port, то все исходящие кадры преобразуются к типу Untagged, то есть из них удаляется дополнительная информация о принадлежности к виртуальной сети. К такому порту можно подключать любое сетевое устройство, в том числе коммутатор, не совместимый со стандартом IEEE 802.1Q, или ПК конечных клиентов, сетевые карты которых не поддерживают работу с виртуальными сетями этого стандарта. Конфигурирование виртуальных сетей стандарта IEEE 802.1Q Рассмотрим конкретные примеры конфигурирования виртуальных сетей стандарта IEEE 802.1Q. Чтобы сформировать VLAN-сеть в соответствии со стандартом IEEE 802.1Q, необходимо проделать следующие действия:
· задать имя виртуальной сети (например, VLAN#1) и определить ее идентификатор (VID);
· выбрать порты, которые будут относиться к данной виртуальной сети;
· задать правила входных портов виртуальной сети (возможность работы с кадрами всех типов, только с кадрами Untagged или только с кадрами Tagged);
· установить одинаковые идентификаторы PVID портов, входящих в виртуальную сеть;
· задать для каждого порта виртуальной сети правила выходного порта, сконфигурировав их как Tagged Port или Untagged Port.
Далее необходимо повторить вышеперечисленные действия для следующей виртуальной сети. При этом нужно помнить, что каждому порту можно задать только один идентификатор PVID, но один и тот же порт может входить в состав различных виртуальных сетей, то есть ассоциироваться одновременно с несколькими VID.
Рассмотренные примеры виртуальных сетей относились к так называемым статическим виртуальным сетям (Static VLAN), в которых все порты настраиваются вручную, что хотя и весьма наглядно, но при развитой сетевой инфраструктуре является довольно рутинным делом. Кроме того, при каждом перемещении пользователей в пределах сети приходится производить перенастройку сети с целью сохранения их членства в заданных виртуальных сетях, а это, конечно, крайне нежелательно. Существует и альтернативный способ конфигурирования виртуальных сетей, а создаваемые при этом сети называются динамическими виртуальными сетями (Dynamic VLAN). В таких сетях пользователи могут автоматически регистрироваться в сети VLAN, для чего служит специальный протокол регистрации GVRP (GARP VLAN Registration Protocol). Этот протокол определяет способ, посредством которого коммутаторы обмениваются информацией о сети VLAN, чтобы автоматически зарегистрировать членов VLAN на портах во всей сети. Все коммутаторы, поддерживающие функцию GVRP, могут динамически получать от других коммутаторов (и, следовательно, передавать другим коммутаторам) информацию VLAN - регистрации, включающую данные об элементах текущей VLAN, о порте, через который можно осуществлять доступ к элементам VLAN и т.д. Для связи одного коммутатора с другим в протоколе GVRP используется сообщения GVRP BPDU (GVRP Bridge Protocol Data Units). Любое устройство с поддержкой протокола GVPR, получающее такое сообщение, может динамически подсоединяться к той сети VLAN, о которой оно оповещено.
Существует и еще один транковый протокол - протокол VTP (VLAN Trunk Protocol), который обеспечивает для каждого устройства (маршрутизатора или коммутатора локальной сети) возможность передачи анонсов в кадрах транкового порта. Эти кадры анонсирования передаются по групповым адресам и принимаются всеми соседними устройствами (но не пересылаются мостами, использующими стандартные процедуры). Анонсы содержат имя области управления (management domain) устройства, номер варианта конфигурации, список известных VLAN вместе с некоторыми их параметрами. Прослушивая эти анонсы, каждое устройство домена управления узнает обо всех новых VLAN, сконфигурированных на передающем анонс устройстве. Использование такого метода позволяет при создании или настройке VLAN проводить все операции на одном устройстве, а все остальные устройства управляемой области получат нужные сведения автоматически. Протокол VTP разработан компанией Cisco.
Ну и напоследок, следует упомянуть транковый протокол ISL Протокол ISL (Inter-Switch Link – межкоммутаторное соединение) используется для соединения коммутаторов Ethernet, поддерживающих VLAN и использующих среды Ethernet MAC и Ethernet. Пакеты в каналах ISL содержат стандартные кадры Ethernet, FDDI или Token Ring, а также связанную с кадром информацию VLAN. Кроме того, в кадре присутствует дополнительная информация. На рисунке показан формат заголовка кадра ISL.
![]()
Заголовок кадра ISL содержит следующие поля:
Адрес получателя
Поле Destination Address содержит 5-байтовый адрес получателя.
Тип кадра
Поле Frame Type указывает тип инкапсулированного кадра и может служить
для обозначения дополнительной инкапсуляции. Определены следующие
типы кадров:
0000 Ethernet
0001 Token Ring
0010 FDDI
0011 ATM
Тип пользователя
0 нормальный приоритет;
1 высший приоритет.
Адрес отправителя
Это поле содержит адрес отправителя пакета ISL. Поле должно содержать
адрес 802.3 MAC порта коммутатора, передающего данный кадр. Поле
адреса имеет размер 48 битов.
Длина
16-битовое поле, указывающее длину пакета в байтах без учета полей DA, T,
U, SA, LEN и CRC. Общая длина неучитываемых полей составляет 18
байтов, поэтому значение данного поля равно общей длине пакета минус 18.
SNAP LLC
3-байтовое поле управления логическим каналом SNAP.
HSA
Поле HSA (High bits of source address – старшие биты адреса отправителя)
содержит три старших байта поля SA.
Идентификатор VLAN
Идентификатор виртуальной ЛВС, к которой относится данный пакет. Это 15-
битовое поле служит для того, чтобы различать кадры разных VLAN. Для
обозначения этого поля часто используют термин color of the packet (цвет
пакета).
Индикатор BPDU и CDP
0 не передается CPU для обработки;
1 передается для обработки CPU.
Индекс
Поле Index показывает индекс порта отправителя пакета в коммутаторе. Это
поле служит для целей диагностики коммутатора и может быть изменено
любым устройством. Поле имеет размер 16 битов и отбрасывается
приемником.
Зарезервировано
Резервное поле.
Для связи между различными VLAN необходимо использовать сетевой уровень, т.е. маршрутизатор. При получении кадра соответствующего транкового протокола, маршрутизатор может изменять в нём поле VID в случае если адрес, на который отправляется кадр соответствует VLAN, отличной от VLAN отправителя. Данный процесс - ничто иное, как простая декапсуляция пакета третьего уровня из кадра второго уровня, и последующая инкапсуляция этого пакета в другой (с другим VID) кадр второго уровня.
Виртуальные локальные сети (VLAN) обеспечивают более гибкое и логичное разбиение сети на сегменты вне зависимости от физического расположения. Применение технологии виртуальных локальных сетей ограничивает поток широковещательных сообщений и тем самым освобождает каналы связи, упрощает управление и сокращает необходимость в дорогих и сложных схемах маршрутизации между коммутируемыми сетями. Использование VLAN дает возможность повысить пропускную способность сети за счет ее эффективной сегментации. В отличие от обычной коммутации, передача информации ограничена только необходимыми адресатами, что приводит к снижению общей загрузки сети. Повышается и уровень защиты информации. Для управления правами доступа можно использовать стандартные средства безопасности.
1.4 Изучение TCP/IP на примерах. Методы защиты от хакеров
Целью данного изложения не является обзор или анализ сетевых атак. В соответствующей лабораторной работе студент воспроизводит несколько сетевых атак, на основе которых изучается работа стека протоколов TCP/IP и дается представление об уязвимости и возможных методах защиты при работе с TCP/IP.
1.4.1 Стек протоколов TCP/IP
Существуют разногласия в том, как вписать модель TCP/IP в модель OSI, поскольку уровни в этих моделях не совпадают. Примером спорного протокола может быть ARP или STP. Мы будем придерживаться следующего соответствия.

Самый нижний (уровень IV) соответствует физическому и канальному уровням модели OSI. Этот уровень в протоколах TCP/IP не регламентируется, но поддерживает все популярные стандарты физического и канального уровня: для локальных сетей это Ethernet, Token Ring, FDDI, Fast Ethernet, 100VG-AnyLAN, для глобальных сетей – примером могут быть протоколы соединений "точка-точка" SLIP и PPP, протоколы территориальных сетей с коммутацией пакетов X.25, frame relay.
Разработана также специальная спецификация, определяющая использование технологии ATM в качестве транспорта канального уровня. Обычно при появлении новой технологии локальных или глобальных сетей она быстро включается в стек TCP/IP за счет разработки соответствующего RFC, определяющего метод инкапсуляции пакетов IP в ее кадры.
Следующий уровень (уровень III) - это уровень межсетевого взаимодействия, который занимается передачей пакетов с использованием различных транспортных технологий локальных сетей, территориальных сетей, линий специальной связи и т. п.
В качестве основного протокола сетевого уровня (в терминах модели OSI) в стеке используется протокол IP. Протокол IP является дейтаграммным протоколом, то есть он не гарантирует доставку пакетов до узла назначения, но старается это сделать.
К уровню межсетевого взаимодействия относятся и все протоколы, связанные с составлением и модификацией таблиц маршрутизации, такие как протоколы сбора маршрутной информации RIP (Routing Internet Protocol) и OSPF (Open Shortest Path First), а также протокол межсетевых управляющих сообщений ICMP (Internet Control Message Protocol). Последний протокол предназначен для обмена информацией об ошибках между маршрутизаторами сети и узлом - источником пакета. С помощью специальных пакетов ICMP сообщается о невозможности доставки пакета, о превышении времени жизни или продолжительности сборки пакета из фрагментов, об аномальных величинах параметров, об изменении маршрута пересылки и типа обслуживания, о состоянии системы и т.п.
Следующий уровень (уровень II) называется основным. На этом уровне функционируют протокол управления передачей TCP (Transmission Control Protocol) и протокол дейтаграмм пользователя UDP (User Datagram Protocol). Протокол TCP обеспечивает надежную передачу сообщений между удаленными прикладными процессами за счет образования виртуальных соединений. Протокол UDP обеспечивает передачу прикладных пакетов дейтаграммным способом, как и IP, и выполняет только функции связующего звена между сетевым протоколом и многочисленными прикладными процессами.
Верхний уровень (уровень I) называется прикладным. За долгие годы использования в сетях различных стран и организаций стек TCP/IP накопил большое количество протоколов и сервисов прикладного уровня. К ним относятся такие широко используемые протоколы, как протокол копирования файлов FTP, протокол эмуляции терминала telnet, почтовый протокол SMTP, используемый в электронной почте сети Internet, гипертекстовые сервисы доступа к удаленной информации, такие как WWW и многие
1.4.2 Работа протокола ARP
Для того чтобы установить соединение, узлам должны быть известны адреса сетевых адаптеров других узлов. Разрешение адреса (address resolution) – это процесс определения аппаратного адреса сетевого адаптера по его IP-адресу. Протокол ARP (Address Resolution Protocol) – часть уровня Интернета модели TCP/IP – позволяет определить адреса сетевых адаптеров, расположенных в одной физической сети.
Протокол ARP нужен для получения адресов сетевых адаптеров TCP/IP-узлов в сетях, поддерживающих широковещание. Он использует широковещательные запросы, содержащие IP-адреса получателя, чтобы выяснить адрес сетевого адаптера этого узла или адрес необходимого шлюза. Получив адрес сетевого адаптера, ARP сохраняет его вместе с соответствующим ip-адресом в своем кэше. Протокол ARP перед формированием широковещательного ARP-запроса всегда ищет в кэше адрес IP и сетевого адаптера.
Протокол ARP описан в RFC 826.
Существуют две процедуры разрешение IP-адреса: разрешение локального IP-адреса и разрешение удаленного ip-адреса.
Разрешение локального ip-адреса.
1. ARP-запрос формируется каждый раз при попытке одного узла связаться с другим.
Если протокол IP определит, что IP-адрес принадлежит локальной сети, узел-отправитель ищет адрес узла-получателя в своем ARP-кэше.
2. Если он не найден, протокол ARP формирует запрос типа “Чей это IP-адрес и каков Ваш адрес сетевого адаптера (MAC адрес )?”, в который так же включаются адреса IP и сетевого адаптера узла-отправителя. ARP-запрос посылается в широковещательном режиме, чтобы все узлы в локальной сети могли принять и обработать его.
3.Каждый узел в локальной сети получает этот широковещательный запрос и сравнивает указанный в нем IP-адрес со своим собственным. Если они не совпадают, запрос игнорируется.
4.Узел-получатель определяет, что IP-адрес в запросе совпадает с его собственным, он посылает на узел-отправитель ARP-ответ, в котором указывает свой адрес сетевого адаптера. Затем он обновляет свой ARP-кэш, занося в него соответствие IP-адреса узла-отправителя адресу его сетевого адаптера.
Разрешение удаленного IP-адреса.
1.При соединении определяется, что IP-адрес узла-получателя принадлежит удаленной сети. Узел-отправитель ищет в локальной таблице маршрутизации путь к узлу-получателю или его сети. Если путь не найден, узел-отправитель определяет IP-адрес шлюза по умолчанию. Затем он ищет в кэше протокола ARP соответствующий ему адрес сетевого адаптера.
2. Если адрес в кэше отсутствует, то широковещательный ARP-запрос используется для получения адреса шлюза. Маршрутизатор (шлюз) в ответ на ARP-запрос узла-отправителя посылает адрес своего сетевого адаптера. Затем узел-отправитель адресует пакет на маршрутизатор для доставки его в сеть получателя и далее – узлу-получателю.
3. На маршрутизаторе выясняется, является ли IP-адрес получателя локальным или удаленным. Если он локальный, маршрутизатор использует протокол ARP (кэш или широковещание) для получения его адреса сетевого адаптера. Если же удаленный, маршрутизатор ищет в своей таблице маршрутизации необходимый шлюз, а затем использует протокол ARP(кэш или широковещание) для получения адреса его сетевого адаптера. Далее пакет отправляется непосредственно следующему получателю в этой цепочке.
И т.д.
Структура пакета.
На компьютере с адресом 172.17.35.49 последовательно были выполнены две команды:
Arp –d
Ping 172.17.35.22
Соответственно, был отправлен arp запрос.
Анализ ARP пакетов в Ethereal:

Соответственно, ARP ответ:

Поле Hardware Type
В поле данного типа помещается признак типа используемого протокола канального уровня. Протоколу Ethernet соответствует значение 1 данного поля.
Поле Protocol Type
В поле данного типа помещается признак типа используемого протокола сетевого уровня. Протоколу IP соответствует значение 0800 данного поля.
Поле HLEN
Задается длина адреса сетевого адаптера в байтах. Для Ethernet длина равна 6 байтам.
Поле PLEN
Задается длина адреса протокола в байтах. Для протокола IP длина равна 4.
Поле Operation
В этом поле размещается признак типа информационного кадра ARP
Поле Sender’s Hardware Address
Задает адрес сетевого адаптера отправителя.
Поле Sender’s Protocol Address
Задается адрес протокола отправителя
1.4.3 АRP атаки
Ложный ARP ответ.
Позволяет удаленно разорвать соединение.


Подмена ARP-информации (ARP Spoofing)
Эта атака, известная также под именем ARP Redirect, перенаправляет сетевой трафик от одной или более машин к машине злоумышленника. Выполняется в физической сети жертвы. Давайте вспомним, что представляет собой протокол ARP и как он работает.
Рассматриваемая атака изменяет кэш целевой машины. Злоумышленник шлет ARP-ответы целевой машине с информацией о новом MAC-адресе, соответствующем (например) IP-адресу шлюза. На самом деле, этот MAC-адрес соответствует интерфейсу машины злоумышленника. Следовательно, весь трафик к шлюзу будет теперь получать машина злоумышленника. Теперь можно прослушивать трафик (и/или изменять его). После этого, трафик будет направляться к реальному целевому адресу и таким образом никто не заметит изменений.
Атака ARP Spoofing используется в локальной сети, построенной на коммутаторах. С ее помощью можно перенаправить поток ethernet-фреймов на другие порты, в соответствии с MAC-адресом. После чего злоумышленник может перехватывать все пакеты на своем порту. Таким образом, атака ARP Spoofing позволяет перехватывать трафик машин, расположенных на разных портах коммутатора.


1.4.4 Протокол TCP
RFC 793
1.4.5 TCP атаки
SYN-наводнение.
Использует свойство протокола TCP - установление виртуального соединения.
Прежде чем начать передачу сегментов, протокол TCP устанавливает виртуальное соединение. Метод установления соединения называется троекратным квитированием и заключатся в обмене пакетами с флагами SYN и АKC. При этом оговариваются так же номера последовательностей и размеры передающего и принимающего окон.
1.При этом устройство, пытающееся установить соединение, посылает сегмент с флагом SYN и ждет ответа SYN-ACK.
2.Если сетевое устройство, с которым устанавливается соединение, готово к установке соединения ( открыт соответствующий порт) то в ответ посылается сегмент с флагами SYN-ACK. Теперь это сетевое устройство ждет сегмента с флагом ACK.
3.Первое устройство, получив SYN-ACK в ответ посылает подтверждение – сегмент с флагом ACK и считает, что виртуальное соединение установлено.
4.Получив сегмент с флагом ACK – второе устройство считает, что соединение установлено.
Вот как это выглядит при анализе с помощью Ethereal:
Здесь мы скопировали только информацию, касающуюся транспортного уровня модели OSI.
С хоста с IP адресом 172.17.35.49 делаем telnet на пор 139 машины с адресом 172.17.35.22. Команда выглядит следующим образом (Windows) :
telnet 172.17.35.22 139
С хоста 172.17.35.49 с “высокого” (>1024 порта ) на хост 172.17.35.22 на порт 139 отправляется сегмент с флагом SYN:

Обратный пакет идет с флагом SYN-ACK

И подтверждение с флагом ACK.

Так же видно, что происходит согласование размеров окон и номеров последовательности. Если процесс останавливается на шаге 2, то второе устройство ожидает некоторое существенное время сегмента подтверждения (ACK). В это время соединение считается полуоткрытым.
Идея атаки состоит в создании большого количества не до конца установленных (полуоткрытых) TCP-соединений. Каждое такое соединение требует ресурсов (например, выделяется оперативная память). Цель – истощить ресурсы. Для реализации этого, злоумышленник посылает множество запросов на установление соединения (пакеты, с выставленным флагом SYN), целевая машина отвечает пакетами SYN-ACK. Злоумышленник же не завершает процесс установки соединения, а оставляет их в полу открытом состоянии. Следовательно, для каждого полученного SYN-пакета сервер выделяет ресурсы и вскоре они исчерпываются. В результате, новые соединения не могут быть открыты. Этот тип отказа в обслуживании направлен только на целевую машину.
2 Задания по курсу «Основы телекоммуникационных технологий»
2.1 Лабораторная работа №1.1 «Построение и моделирование локальной сети с несколькими источниками трафика»
2.1.1 Цель: изучение системы моделирования NetCracker. Построение модели локальной сети (на базе технологии Ethernet) с несколькими источниками трафика в системе моделирования NetCracker.
2.1.2 Круг вопросов, который студент должен изучить в процессе занятия
13. Система моделирования NetCracker.
- Общий интерфейс системы моделирования NetCracker
- Выбор и настройка оборудования в системе NetCracker
- Понятие о статистических распределениях. Моделирование сетевого трафика в системе NetCracker.
- Сбор статистики с моделей устройств в системе NetCracker.
14. Ethernet.
- Общие понятия о технологии Ethernet
- Общие понятия о оборудовании, поддерживающем технологию Ethernet
15. Практические навыки.
- Основные навыки моделирования сетей в системе NetCracker
- Умение построить математическую модель трафика, проходящего по сети, на основе знаний о статистических распределениях.
2.1.3 Общий план
1. Знакомство с различными статистическими распределениями и методами создания математической модели реального трафика.
2. Изучение интерфейса системы моделирования NetCracker.
3. Способы настройки моделей оборудования в системе NetCracker.
4. Моделирование сетевого трафика в системе NetCracker.
5. Сбор и анализ статистики с моделей оборудования в системе NetCracker.
2.1.4 Предварительные требования
К программному обеспечению и оборудованию.
Компьютеры с установленной Windows 98,2000,XP.
Должна быть установлена программа NetCracker Professional версии 3.2 или выше.
К студентам: знакомство с технологией Ethernet, начальные знания в области теории вероятности и статистических распределений.
2.1.5 Развернутый план
2.1.5.1 Знакомство с методами математического моделирования реального трафика
При математическом моделировании сети, как правило, пользуются аппаратом Теории массового обслуживания (ТМО), англоязычное название – queuing theory (теория очередей). Эта теория изучает ситуации, когда имеется некоторый ограниченный ресурс и множество (поток) запросов на его использование, следствием чего являются задержки или отказы в обслуживании некоторых запросов. Важным этапом в применении ТМО для исследования реального объекта является формальное описание этого объекта в терминах той или иной системы массового обслуживания (СМО). СМО считается заданной, если полностью описаны следующие ее компоненты:
· Входящий поток запросов (заявок, требований, сообщений, вызовов)
· Количество и типы обслуживающих устройств (приборов)
· Емкости накопителей (буферов), где запросы, заставшие все приборы занятыми, ожидают начала обработки
· Времена обслуживания запросов в приборах
· Дисциплина обслуживания (определяет порядок обработки запроса в системе, начиная с момента его поступления в систему и до момента, когда он ее покидает)
Согласно символике Дж. Кендалла, введенной в 1953 году, в ТМО принято кодирование основных СМО в виде четырех символов, разделенных вертикальными чертами: A|B|n|m. Символ n, n ³ 1 задает число идентичных параллельных обслуживающих устройств. Символ m, m ³ 1 задает число мест для ожидания в буфере. Символ А описывает входящий поток запросов, а символ В – распределение времен обслуживания запросов.
Прежде всего, в данной лабораторной работе нас будут интересовать такие характеристики СМО, как входящий поток и время обслуживания. Основная характеристика входящего потока – функция распределения времен поступления заявок в систему. В рамках данной работы студенты должны изучить следующие распределения:
· Равномерное
· Показательное (экспоненциальное)
· Нормальное
· Эрланговское
· Вейбулла
Время обслуживания заявок в системе будет задаваться выставлением простейшей задержки для каждого устройства, а так же, заданием вида распределения размера пакета (заявки). Для простоты будем считать, что время обслуживания заявки линейно зависит от ее размера.
2.1.5.2 Изучение интерфейса системы моделирования NetCracker
2.1 Запуск программы NetCracker Professional. Основные меню, выбор моделей оборудования для моделирования сети.
2.2 Студенты должны смоделировать простейшую сеть, состоящую из двух рабочих станций и коммутирующего оборудования. Модели оборудования выбираются по заданию преподавателя.
2.1.5.3 Изучение способов настройки моделей оборудования
3.1 В данной части работы, студенты должны настроить используемые ими модели рабочих станций. А именно: установить в оборудование дополнительные платы/юниты и специальное программное обеспечение.
3.2 Следующим этапом работы будет настройка коммутирующего оборудования. Студентам необходимо настроить интерфейсы данного оборудования и дать ему описание, соответствующее модели сети.
2.1.5.4 Моделирование сетевого трафика в системе NetCracker
4.1 Студенты должны смоделировать трафик между двумя рабочими станциями. Параметры моделируемого трафика назначаются преподавателем каждому студенту индивидуально. При этом, преподаватель должен обсудить со студентом, какая модель в данном случае наиболее правильно описывает реальный трафик. Это обсуждение будет составлять часть оценки студента за данную лабораторную работу.
2.1.5.5 Сбор и анализ статистики с моделей оборудования в системе NetCracker
Студентам необходимо научится снимать статистику с каждой модели устройства в их сети. Статистика может выводиться в цифровом, графическом и процентном видах. Студенты должны обосновать выбор того или иного способа вывода статистики для конкретного измеряемого параметра.
Собираемая статистика: утилизация канала связи, нагрузка на устройство, время доставки пакетов, количество потерянных пакетов.
Статистика должна последовательно сниматься с сети, содержащей сначала две рабочие станции, затем три и окончательной версии сети, содержащей 6 рабочих станций. В качестве коммутирующего оборудования должен быть выбран концентратор Ethernet. Студентам необходимо проследить зависимость измеряемых параметров от количества рабочих станций в сети и интенсивности трафика. Полученные результаты оформляются в тетрадях, по ним строятся графики и на основании этих результатов студенты делают выводы об эффективности работы технологии Ethernet.
2.2 Лабораторная работа №1.2 «Анализ трафика с помощью Ethereal»
2.2.1 Цель: изучение структуры кадра Ethernet. Знакомство со спецификациями Ethernet II и IEEE 802.3/802.2.
2.2.2 Круг вопросов, который студент должен изучить в процессе занятия
2.2.3 OSI
a. Горизонтальная и вертикальная составляющие модели OSI
b. Инкапсуляция в OSI
c. Какие уровни OSI соответствуют работе Ethernet II, IEEE 802.3, IEEE 802.2
2.2.4 Ethernet.
d. Несколько спецификаций Ethernet, в чем различие
e. Подробный анализ заголовка кадра Ethernet II
f. MAC адресация. Структура MAC адреса. Широковещательный MAC адрес.
2.2.5 Практические навыки.
g. Умение пользоваться Ethereal
h. Способность сгенерировать и послать произвольный (сырой [RAW]) пакет в сеть
i. Общее представление о принципе работы PCAP и подобных решений.
2.2.6 Общий план
1. Знакомство с сетевым анализатором Ethereal.
2. Принцип инкапсуляции
3. Подробное (побитное) рассмотрение кадра Ethernet II
4. Отличия Ethernet II от IEEE 802.3/802.2
5. Широковещательность Ethernet
2.2.7 Предварительные требования
1. К программному обеспечению и оборудованию.
Windows 98,2000,XP.
Должна быть установлена программа Ethereal. Для ее работы необходимо предварительно установить WinPCAP. (см. ссылку /1/)
В пункте 4 мы будем пользоваться несколькими программами, написанными на perl. Для того чтобы эти программы заработали нужно
· Установить ActivePerl (http://www.activeperl.com/)
· Установить WinPCAP (http://www.winpcap.org/)
· Загрузить модули (см. ссылку /2/)
1. NetPacket
ppm install http://www.bribes.org/perl/ppm/NetPacket.ppd
2. Net::Pcap
ppm install http://www.bribes.org/perl/ppm/Net-Pcap.ppd
3. Net::PcapUtils
ppm install http://www.bribes.org/perl/ppm/Net-PcapUtils.ppd
4. Win32::NetPacket
ppm install http://www.bribes.org/perl/ppm/Win32-NetPacket.ppd
· Так же потребуется программа Ethereal (http://www.ethereal.com/)
В данном пункте используются 2 программы, написанные на perl (см. ссылку /4/)
uncode_packet.pl – переводит файл из формата tcpdump в текстовый формат. Потом этот файл можно открыть notepad и произвести соответствующие изменения.
send_raw_packet.pl – посылает сырой пакет текстового формата.
программа Ethereal
2. К студентам: знакомство с Ethernet, представление об OSI модели.
2.2.8 Развернутый план.
2.2.8.1 Знакомство с сетевым анализатором Ethereal
1.1 Принцип работы WinPcap.
Главная мысль – работает в обход стека TCP/IP (см. ссылку /3/)
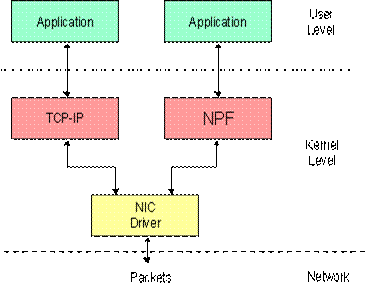
 NPF
inside NDIS
NPF
inside NDIS
1.2 Запустить программу Ethereal. Cupture/Start.
Обратить внимание на название драйвера на (типа Intel(R) PRO Adapter: Device\NPF_{A52CA0CA-077B-4240-83E3-8017213EE340}). Ключевое слово NPF.
Внимание: программа будет работать только под логином администратора.
1.3 Пронаблюдать сетевую активность. Если ничего нет, послать какой-нибудь пакет, например, командой ping. Остановить захват пакетов.
1.4 Исследовать функциональные возможности программы. Последовательно рассмотреть все пункты меню.(Особенное внимание обратить на возможности фильтрации).
2.2.8.2 Принцип инкапсуляции
2.1 Командой “ipconfig /all” определить ip адрес компьютера.
Начать захват пакетов. Послать ping соседу. Остановить захват.
Проанализировать структуру icmp пакета.
Необходимо обратить внимание на инкапсуляцию. Вложение: заголовок кадра, заголовок пакета, данные.
2.2 Командой “netstat –a” определить открытые tcp порты
(пока ничего объяснять не надо, пусть просто сделают. Объяснения и детальное ознакомление – это тема другой лаб. работы).
Начать захват пакетов. Сделать telnet на открытый tcp порт соседа. Остановить захват. Найти tcp пакет.
Обратить внимание на инкапсуляцию: заголовок кадра, заголовок пакета, заголовок сегмента, данные.
2.2.8.3 Подробное рассмотрение кадра Ethernet II
3.1 Взять любой кадр. Выделить в заголовке Ethernet II Destination MAC address, source MAC address, Type. Подробно обсудить смысл MAC адреса и значение отдельных полей.
3.2 Начать захват пакетов. Выполнить команду “arp -a”. Посмотреть на arp таблицу. (Пока без объяснений). Выполнить команду “arp –d”. Опять выполнить команду “arp –a”. Убедиться, что таблица пуста. Выполнить ping соседа. Остановить захват пакетов. Найти arp запрос. Убедиться, что он имеет широковещательный MAC адрес.
2.2.8.4 Отличия Ethernet II от IEEE 802.3/802.2
4.1 Открыть с помощью Ethereal кадр (приготовленный заранее) IEEE 802.3/802.2 (например, Cisco BPDU STP). Сравнить его с кадром Ethernet II. Подробно поговорить о протоколе 802.2
2.2.8.5 Широковещательность Ethernet
5.1 Создание и отправление в сеть “сырого” кадра. Последовательность действий.
- Запустить ethereal. Запустить захват пакетов
- Выполнить ping на соседний компьютер
- Остановить захват пакетов.
- Найти свой Echo (ping) request (протокол icmp).
- Выделить его.
- Сохранить. Присвоить ему имя, например ping (внимание: сохранить надо только его, а не все пакеты)
- Запустить программу uncode_packet.pl
- Ввести файл ping в качестве входного и создать выходной файл, назвав его, например, ping_uncode.
- Созданный файл (ping_uncode) открыть Notepad и изменить destination mac address на широковещательный, назвав новый файл, например, ping_uncode_new.
- Запустить захват пакетов.
- С помощью программы send_raw_packet.pl переслать новый пакет (ping_uncode_new) в сеть.
- Остановить захват пакетов.
- Убедиться, что был получен ответ.
- Повторить ту же процедуру, поменяв на широковещательный source mac address.
Внимание: создавая файлы, обращайте внимание на расширения. Чтобы не было путаницы, лучше создавать файлы без расширения.
2.2.9 Ссылки
/1/ О программе + download
Свободное распространение на основе Стандартной Общественной Лицензии GNU.
http://www.gnu.org/licenses/gpl.html
Русский перевод Стандартной Общественной Лицензии GNU можно прочитать, например, http://linux.yaroslavl.ru/docs/about/license/gplrus.html
Требует предварительной установки winPcap
License для WinPcap
http://www.winpcap.org/misc/copyright.htm
/2/ http://www.bribes.org/perl/ppmdir.html
/3/ http://www.winpcap.org/winpcap/docs/man/html/group__NPF.html
/4/ Ниже приведены коды программ:
#Uncode_packet.pl
# Программа переводит файл формата tcpdump в текстовый формат.
# В дальнейшем, новый файл можно исправлять и посылать
#с помощью программы send_raw_packet в сеть
# Написана Романом Елохиным, 2005 год
#!/usr/bin/perl -w
# use strict;
use Net::Pcap;
use Net::PcapUtils;
use NetPacket::Ethernet;
use Win32::NetPacket;
if (!(defined $ARGV[0])){
print "Enter the name of first file: \n";
$file_from = <STDIN>;
chomp $file_from;
print "Enter the name of second file: \n";
$file_to = <STDIN>;
chomp $file_to;
}
else {
if ($#ARGV > 1){
print " Err. More then 2 files\n";
}
else {
$file_from = $ARGV[0];
$file_to = $ARGV[1];
}
}
open (FD, ">$file_to") or die;
sub callback_fn {
my ($user_data, $hdr, $pkt) = @_;
my @t = unpack ("C*", $pkt);
my $i=0;
@t_hex=();
foreach $t_element (@t){
$t_hex[$i] = sprintf ('%X', $t_element);
$i++;
}
$t_hex = join (" ", @t_hex);
print "\n$n\n\n $t_hex\n";
print FD $t_hex;
$n++;
}
Net::PcapUtils::loop(\&callback_fn, SAVEFILE => "$file_from");
close FD;
#send_raw_packet.pl
#Программа посылает в сеть произвольную шестнадцатеричную
#последовательность данных в текстовом формате
# (например, созданных NotePad). Байты должны отделяться пробелом.
#Написана Романом Елохиным, 2005 год.
#!/usr/bin/perl -w
# use strict;
use Net::Pcap;
use Net::PcapUtils;
use NetPacket::Ethernet;
use Win32::NetPacket;
if (!(defined $ARGV[0])){
print "Enter the name of first file: \n";
$file_from = <STDIN>;
chomp $file_from;
print "Enter the name of second file: \n";
$file_to = <STDIN>;
chomp $file_to;
}
else {
if ($#ARGV > 1){
print " Err. More then 2 files\n";
}
else {
$file_from = $ARGV[0];
$file_to = $ARGV[1];
}
}
open (FD, ">$file_to") or die;
sub callback_fn {
my ($user_data, $hdr, $pkt) = @_;
my @t = unpack ("C*", $pkt);
my $i=0;
@t_hex=();
foreach $t_element (@t){
$t_hex[$i] = sprintf ('%X', $t_element);
$i++;
}
$t_hex = join (" ", @t_hex);
print "\n$n\n\n $t_hex\n";
print FD $t_hex;
$n++;
}
Net::PcapUtils::loop(\&callback_fn, SAVEFILE => "$file_from");
close FD;
2.3 Лабораторная работа №2.1 «Адресные схемы протокола IP»
2.3.1 Цель: изучение логической адресации протокола IP и построение определенного адресного пространства с использованием технологий CIDR и VLSM.
2.3.2 Круг вопросов, который студент должен изучить в процессе занятия
1. Протокол IP
a. Формат пакета протокола IP.
b. Логическая адресация в протоколе IP, классы IP адресов, маски подсетей, основные понятия маршрутизации.
c. Технология междоменной бесклассовой маршрутизации (CIDR) и использование масок подсетей переменной длины (VLSM).
2 Моделирование адресных схем протокола IP в системе NetCracker
a. Настройка IP адресов на моделях оборудования в системе NetCracker
b. Модели маршрутизаторов и их использование в модели сети в системе NetCracker
c. Использование приложения IP Planner в системе NetCracker
3 Практические навыки
a. Способность создавать адресные схемы в рамках протокола IP и технологий CIDR и VLSM
b. Умение моделировать в системе NetCracker адресные схема протокола IP и строить модель сети с использованием маршрутизаторов и приложения IP Planner.
2.1.1 Общий план
1. Разбор принципов работы протокола IP
2. Классы IP адресов и классовая маршрутизация
3. Бесклассовая маршрутизация и использование масок подсетей переменной длины
4. Освоение моделирования работы протокола IP и построения модели сети с использованием маршрутизаторов в системе NetCracker
5. Использование приложения IP Planner в системе NetCracker
2.1.2 Предварительные требования
1. К программному обеспечению и оборудованию.
Компьютеры с установленной Windows 98, 2000, XP.
Должна быть установлена программа NetCracker Professional версии 3.2 или выше.
2. К студентам: знакомство с протоколом IP и технологиями CIDR и VLSM, начальные знания в области маршрутизации
2.1.3 Развернутый план
2.1.3.1 Принципы работы протокола IP
1.1 Формат пакета протокола IP. Поля заголовка пакета IP.
1.2 Сравнение «плоской» (физической) адресации канального уровня модели OSI с иерархической (логической) адресацией сетевого уровня модели OSI.
2.1.3.2 Классы IP адресов. Классовая маршрутизация.
2.1 Изучение классов IP адресов – каждый студент должен по заданию преподавателя объяснить принципы «кодирования» класса в первом октете IP адреса, а также подсчитать количество сетей различных классов и количество хостов в них.
2.2 Специализированные классы IP адресов (multicast и т.д.) и служебные сети (loopback, private networks и т.д.).
2.3 Недостатки классовой маршрутизации. Дефицит адресного пространства протокола IPv4.
2.1.3.3 Бесклассовая маршрутизация.
3.1 Маски подсетей. Различные способы записи маски подсети.
3.2 Маски подсетей переменной длины, технология VLSM. Студентам предлагается создать адресную схему сети, разделяя на подсети с различным количеством хостов сеть класса В, например 174.11.7.0, с помощью технологии VLSM. Каждый студент получает уникальное задание у преподавателя. Оценка за это задание будет составлять часть оценки студента за данную лабораторную работу.
3.3 Изучение принципов бесклассовой междоменной маршрутизации, технология CIDR.
Преимущества бесклассовой маршрутизации перед классовой маршрутизацией.
2.1.3.4 Моделирование работы протокола IP. Создание модели сети с использованием маршрутизаторов в системе моделирования NetCracker .
4.1 Студентам необходимо смоделировать сеть, содержащую две логические подсети и соединить их с помощью модели маршрутизатора. При этом, каждой рабочей станции обеих логических подсетей присваивается IP адрес данной подсети.
4.2 Студенты производят настройку модели маршрутизатора, соединяющего две логические подсети.
2.1.3.5 Использование приложения IP Planner в системе NetCracker.
5.1 Изучение работы приложения IP Planner в системе NetCracker. Студенты должны, применив приложение IP Planner, присвоить адреса рабочим станциям моделируемой сети.
5.2. Наконец, студенты разделяют выделенное адресное пространство на подсети с масками переменной длины, используя приложение IP Planner.
2.2 Лабораторная работа №2.2 «Изучение принципов работы маршрутизатора»
2.2.1 Цель: дать представление о работе сети на третьем уровне модели OSI.
2.2.2 Круг вопросов, который студент должен изучить в процессе занятия
1. Протокол ip
a. Идентификатор хоста, идентификатор сети, маска сети, подсети.
b. Маршрутизация пакета
c. Таблица маршрутизации
d. Динамическая и статическая маршрутизация
e. Структура заголовка ip пакета.
2. Оборудование.
a. Назначение маршрутизатора
b. Принцип работы маршрутизатора
c. Общее представление об устройстве маршрутизатора
3. Практические навыки. Студент должен
a. научиться настраивать таблицы маршрутизации
b. выполнять настройки ip протокола (адрес, сеть, маска, шлюз)
c. уметь подключать маршрутизатор к локальной сети
d. иметь представление о возможностях диагностики работы сети (ping, telnet, trace, ACL, debag, show…)
2.2.3 Общий план
1. Введение. Знакомство с маршрутизатором на примере маршрутизатора Cisco серии 800, 1000, 1600, 1700 или 2500 (один из – какой будет в наличии)
2. Назначение маршрутизатора. Таблица маршрутизации.
3. Принцип работы маршрутизатора. Структура ip пакета. Последовательность действий при маршрутизации пакета.
2.2.4 Предварительные требования
1. К программному обеспечению и оборудованию.
Операционная система : Windows 98, 2000
Должны быть установлены следующие программные продукты: WinPcap, Ethereal
Оборудование: Router Cisco 800, 1000, 1600, 1700, 2500 (любой из)
Технологии: Локальная сеть Ethernet
2.2.5 Развернутый план
2.2.5.1 Знакомство с маршрутизатором на примере маршрутизатора Cisco
1.1 Внешний вид маршрутизатора.
· Различные порты
(Ethernet, Serial, Consol). LAN, WAN, нарисовать пример сети с использованием технологий WAN и LAN, указать место маршрутизатора и способ подключения. Протоколы физического уровня. RS-232 (Consol), V.35, V.24 (Serial), 10-BaseT, 10Base-5, 10Base-2 (Ethernet), 100Base-TX, 100Base-FX, 100Base-T4 (FastEthernet)
(коротко, на уровне терминов, должны просто представлять, что могут быть разные интерфейсы)
· Flash
Различные виды памяти. Flash, RAM, NVRAM, ROM. Назначения. (Так же коротко, как справку…)
1.2 Подключить маршрутизатор к локальной сети.
· Подключить консоль
· Запустить терминальную программу (например, HyperTerminal) Настройки RS-232: bps = 9600, DataBits = 8, Parity = None, Stop bits = 1
· Проверить, что flash карта вставлена (на ней должен быть “правильный” IOS) и включить питание.
· Сконфигурировать Ethernet интерфейс.
· Подсоединить к сети. (рассказать о прямом и кросс соединении )
1.3.Выполнение диагностических команд.
· Ping, telnet, trace
· Term mon, Deb ip icmp, no deb all, term no mon. Внимание: запрещается вводить команду deb all.
1.4.Элементы управления трафиком на основе ip адресов
· Создать стандартный список доступа, запрещающий хождения с некоторых адресов сети (при этом должны оставаться такие, с которых ходить можно)
· Прописать его на Ethernet интерфейсе (на in или out, по желанию и в зависимости, конечно, от того, как устроен список доступа)
· Выполнить команды ping с разных адресов (запрещенных и разрешенных). Какой результат?
· Снять список доступа с интерфейса
· Поставить список на line vty
· Попытаться выполнить telnet соединение с разных ip адресов (какой результат?). Внимание: число telnet соединений ограничено (например, 5)
· Снять список доступа с line vty
· Выполнить команду Deb ip packet det номер_списка_доступа. Затем ввести команду term mon. Выполнить команду ping с одного из компьютеров. Проанализировать полученную информацию.
· Выполнить команды no deb all, term no mon
2.2.5.2 Таблица маршрутизации.
2.1 Посмотреть таблицы маршрутизации на Router и на компьютере (Windows)
· Выполнить команду sh ip route на маршрутизаторе.
· Выполнить команду route print на компьютере.
· Объяснить вывод этих команд.
2.2 Шлюз по умолчанию.
· Прописать на маршрутизаторе шлюз по умолчанию. Выполнить ping на внешний адрес. Убедиться, что работает.
· Запустить Ethereal. Начать захват пакета. Выполнить команду ping внешнего адреса (например, www.ru) . Остановить захват пакетов. Убедиться, что destination mac address фрэйма icmp пакета – mac адрес шлюза по умолчанию.
· Начать захват пакетов. Выполнить команду ping на адрес 1.1.1.1. Остановить захват пакетов. Проанализировать результат.
· Начать захват пакетов. Выполнить команду ping на ip адрес соседа. Остановить захват пакетов, проанализировать результат.
2.3 Изменение таблицы маршрутизации
· На интерфейсе маршрутизатора Serial 0 выполнить команду no keepalive
· Прописать на нем ip адрес (например, 1.1.1.1 /24 )
· Выполнить команду sh interface serial 0. Убедиться, что маршрутизатор диагностирует физическое соединение как UP.
· Выполнить команду sh ip route. Убедиться, что новая сетка (1.1.1.0 255.255.255.0) присутствует в роутинговой таблице.
· Попытаться выполнить команду ping с одного из компьютеров локальной сети. Объяснить результат
· Проверить с помощью Ethereal
· Изменить таблицу маршрутизации на компьютере таким образом, чтобы ping проходил
· Нарисовать более сложную сеть. (Предположим, например, что через интерфейс Serial 0 подключен еще один маршрутизатор, к Ethernet интерфейсу которого подключена другая локальная сеть). Задать идентификаторы сетей (WAN сеть между последовательными интерфейсами маршрутизаторов и новая LAN сеть), задать ip адреса интерфейсов и маски сетей.
· Если есть второй маршрутизатор, то можно выполнить этот пункт задания на практике. (При этом на Ethernet интерфейсе второго маршрутизатора надо ввести команду no keepalive, если мы его никуда не хотим подсоединить или подсоединить его к отдельно стоящему компьютеру или даже сегменту сети. Но при этом придется настраивать, соответственно, ip адреса всех компьютеров в этом сегменте)
· Изменить таблицы маршрутизации, чтобы пакеты ходили между локальными сетями?
2.4 Статическая и динамическая маршрутизации.
· Сконфигурировать router rip на маршрутизаторе.
· Запустить deb ip rip. Выполнить term mon. Запустить Ethereal, начать перехват пакетов. После несольких rip обновлений остановить перехват.
· Ознакомиться со структурой rip пакета.
· Несколько слов надо сказать и о других протоколах маршрутизации (OSPF, BGP).
2.2.5.3 Последовательность действий, выполняемых маршрутизатором при маршрутизации пакета
3.1С помощью Ethereal изучить структуру ip заголовка.
· Version
· Differentiated Services Codepoint
· Total Length
· Identification, flags, fragment Offset
· TTL
· Protocol
· Header Checksum
· Ip addresses (source, destination)
3.2 Последовательность операций, выполняемых маршрутизатором при маршрутизации пакета.
2.3 Лабораторная работа №3.1 «Построение локальной сети с применением коммутаторов и технологий VLAN»
2.3.1 Цель: изучение принципов построения современной локальной сети с использованием коммутаторов и технологий VLAN.
2.3.2 Круг вопросов, который студент должен изучить в процессе занятия
3. Коммутаторы.
- Принципы работы коммутатора и понятия коллизионного домена и сегментации.
- Адресная таблица коммутатора.
- Методы коммутации: с промежуточным хранением (store-and-forward) и сквозной метод (cut-through).
4. Технологии VLAN.
- Статические и динамические VLAN.
- Использование таблиц фильтрации и меток (tag) в заголовках кадров. Протокол IEEE 802.1Q.
- Маршрутизаторы в виртуальных сетях.
5. Практические навыки.
- Знание технологий VLAN и умение строить сеть с их использованием.
- Знание протокола IP и умение строить адресные схемы на его основе.
- Общие навыки настройки оборудования (коммутаторов и маршрутизаторов).
2.3.3 Общий план
1. Осуждение схемы построения сети.
2. Знакомство с оборудованием.
3. Настройка нескольких виртуальных сетей на коммутаторе (группа делится на несколько подгрупп, каждой из которых выделяется отдельная виртуальная сеть).
4. Настройка поддержки виртуальной сети на интерфейсе маршрутизатора.
5. Выделение IP подсети для каждой виртуальной сети.
6. Управление доступом из одной виртуальной сети в другую.
2.3.4 Предварительные требования
1. К программному обеспечению и оборудованию.
Компьютеры с установленной Windows 98,2000,XP.
Коммутатор с поддержкой VLAN (IEEE 802.1Q).
Маршрутизатор.
- К студентам: Знание протокола IP, принципов работы коммутатора, технологий VLAN. Общие понятия о работе маршрутизатора.
2.3.5 Развернутый план
2.3.5.1 Схема построения сети
1.1 Схема лабораторной сети с несколькими VLAN:
![]()
1.2 Обсуждение преимуществ данной схемы сети по сравнению с сетью без применения VLAN.
2.3.5.2 Знакомство с оборудованием
2.1 Изучение консоли управления коммутатора
- Изучение общего вида консоли управления
- Изучение меню консоли управления либо синтаксиса командной строки коммутатора
- Определение параметров настройки коммутатора, необходимых для создания VLAN
2.2 Изучение консоли управления маршрутизатора
- Изучение общего вида консоли управления
- Изучение синтаксиса командной строки маршрутизатора
- Определение параметров настройки маршрутизатора, необходимых для поддержки и управления доступом VLAN
2.3.5.3 Настройка VLAN на коммутаторе
· Каждая из подгрупп, на которые разделена группа, настраивает свой VLAN на коммутаторе. Для этого выбирается VLAN ID, а также назначаются конкретные порты коммутатора, как tagged и untagged порты, принадлежащие данному VLAN.
· Студенты должны объяснить выбор портов и настройку их как порты определенного типа.
2.3.5.4 Настройка VLAN на маршрутизаторе
· Каждая из подгрупп, на которые разделена группа, настраивает свой сабинтерфейс на маршрутизаторе и задает на нем нужный тип инкапсуляции кадров.
· Все адресное пространство учебной лаборатории делится студентами на подсети, адреса которых присваиваются компьютерам и сабинтефейсам маршрутизатора соответствующих VLAN.
2.3.5.5 Настройка прав доступа из одной VLAN в другую
· Преподаватель раздает каждой подгруппе задание на создание правил доступа во VLAN этой подгруппы
· Студенты применяют созданные ими права доступа на маршрутизаторе и проверяют работоспособность всей локальной сети лаборатории в целом.
2.4 Лабораторная работа №3.2. «Атаки с использованием уязвимости стека протоколов TCP/IP и защита от них»
2.4.1 Цель: изучить работу стека протокола TCP/IP.
2.4.2 Круг вопросов, который студент должен изучить (или закрепить) в процессе занятия. (/1/, /4/, /5/)
1. Стек протоколов TCP/IP
a. Многоуровневая структура стека (DOD модель)
b. TCP
· Установление и завершение соединения. Тройное квитирование.
· Взаимодействие с приложением. Сокеты. Порты. Сервер – клиент.
· Надежная доставка
1. Квитирование. Нумерация октетов
2. Контрольная сумма
3. Повторная передача
· Управление потоком. Скользящее окно.
· Флаги. (syn, fin, ack, rst, push, urg)
c. UDP
· Отличие от TCP
· Преимущества и недостатки по сравнению с TCP
d. IP (должен был быть изучен ранее, поэтому здесь только о взаимодействии с другими протоколами стека TCP/IP)
· Взаимодействие с протоколами транспортного уровня (UDP, TCP)
· Взаимодействие с протоколами канального уровня. Arp таблица
e. ARP
· Arp таблица
· Алгоритм работы, arp cash, arp запрос, arp ответ
· Структура arp пакета.
f. Icmp (коротко)
· Назначение
· Ping
· Traceroot
· Структура пакета
2. Протокол RIP.
a. Структура rip пакета.
b. Принципы RIP
c. Другие протоколы маршрутизации.
2.4.3 Общий план
1. Изучение с помощью Ethereal принципов работы ARP протокола
2. Изучение помощью Ethereal принципов работы протокола TCP
3. Изучение с помощью Ethereal принципов работы протокола UDP
4. Атаки, использующие уязвимости возможных реализаций ARP протокола
5. Атаки, использующие уязвимости возможных реализаций IP протокола
6. Атаки на основе принципа работы TCP протокола
7. Атаки, использующие уязвимости возможных реализаций RIP протокола
2.4.4 Предварительные требования
1. К программному обеспечению и оборудованию.
Те же, что и в лабораторной работе №2.1
2. К студентам.
Выполненные работы 2.1 и 2.2. В данной работе используется знание и навыки, полученные в предыдущих лаб. работах
2.4.5 Развернутый план
2.4.6 Изучение с помощью Ethereal принципов работы протокoла ARP.
1.1. ARP таблица. ARP кэш.
· Выполнить команду arp –a. Если таблица пуста, выполнить ping на любой ip адрес. Выполнить команду arp –a. Объяснить вывод.
· Выполнить команду arp –d. Убедиться, что кэш пуст. Выполнить команду на внешний адрес. Посмотреть таблицу. Объяснить результат.
1.2 ARP запросы, ARP ответы.
· Начать перехват пакетов с помощью Ethereal. Очистить таблицу. Выполнить ping. Остановить перехват. Найти arp пакеты. Объяснить результат.
· Выполнить команду arp –a. Объяснить результат.
· Изучить структуру arp пакета. ( зарисовать)
2.4.7 Изучение с помощью Ethereal принципов работы протокола TCP.
2.1 Установление виртуального канала. Троекратное квитирование.
· Начать перехват пакетов. Выполнить telnet на открытый порт соседа (если есть Internet, можно выполнить telnet на 80 порт любого сайта, например www.ru). Произвести передачу данных (если это сайт, то ввести команду get). Завершить сессию (Quit или Exit – может быть по-разному). Завершить перехват пакетов.
· Увидеть последовательность SYN – SYN ACK – ACK
· Какие tcp параметры ”оговариваются” во время установления соединения? (ip адреса, порты, протокол [tcp или udp], SN, размер окна)
2.2 Завершение сессии
· Увидеть последовательность FIN ACK – ACK, FIN ACK – ACK, если сессия была завершена корректно (командой выхода) и RST, если некорректно. Значение флага RST.
2.3 Передача данных. Надежная доставка, управление потоком.
· При анализе структуры сегментов при передаче данных обратить внимание на функционирование SN, на размер скользящего окна, на флаг ACK, на контрольную сумму.
· Зарисовать структуру tcp заголовка.
2.4.8 Изучение с помощью Ethereal принципов работы протокола UDP
· Начать перехват пакетов. По сети запустить приложение, работающее через UDP (multimedia) . Остановить перехват пакетов.
· Изучить работу протокола.
· Зарисовать UDP заголовок
2.4.9 Атаки, использующие уязвимости возможных реализаций ARP протокола
4.1 Пример атаки: Удаленный разрыв соединения. /2/ , /4/, /5/
· Участвуют 3 компьютера. Два находятся в состоянии обмена данными, например, выполняют команду ping или установлено telnet соединение. При этом один является сервером, другой клиентом. Третий (злоумышленник) посылает клиенту “неправильный” ARP пакет, разрывая соединение.
· “Неправильный” ARP пакет является arp reply, в котором указан неправильный mac адрес сервера. Для создания такого пакета используется Ethereal и программы Uncode_raw_packet.pl и notepad.exe. Для посылки пакета - send_raw_packet.pl
4.2 Нарисовать схему атаки “ARP PROXY”
2.4.10 Атаки, использующие уязвимости возможных реализаций IP протокола.
5.1 Пример атаки: LAND /3/, /4/, /5/
· Создаем шаблон, который будем менять. Нас интересует tcp syn пакет на открытый порт. Создаем с использованием Ethereal.
· Меняем source ip адрес, source порт и source mac адрес (все это должно быть равно destination, чтобы заставить операционную систему посылать самой себе пакет)
· Выставляем правильно контрольные суммы.
· Посылаем пакет в сеть. При этом наблюдаем анализатором трафика.
· Что произошло?
2.4.11 Атаки, на основе принципа работы TCP протокола.
6.1 Пример атаки: полуоткрытое соединение. С помощью “неправильного” ARP ответа.
· Начинаем перехват пакетов.
· Посылаем “неправильный” ARP ответ, в котором говорим оппоненту наш “неправильный” mac адрес.
· Делаем telnet на открытый порт.
· Проанализировать данные Ethereal.
6.2 Полуоткрытое соединение с помощью изменения ip
· Создаем шаблон tcp syn пакета.
· Меняем source ip адрес.
· Посылаем “неправильный” arp ответ, в котором устанавливаем соответствие нового ip адреса и нашего mac адреса.
· Посылаем пакет.
· Что происходит? Что происходит, если такой (на который мы заменяем) ip адрес в сету уже есть?
6.3 Обсудить возможность атаки “перехват tcp соединения”
2.4.12 Атаки на основе принципа работы rip протокола.
e. Пример атаки: несанкционированное изменение таблицы маршрутизации.
· С помощью маршрутизатора, подключенного в сеть создать пакет rip обновления. Записать.
· Изменить таким образом, чтобы маршрутизатор изменил свою таблицу маршрутизации.
· Послать пакет.
· Проверить, изменилась ли таблица маршрутизации.
2.4.13 Ссылки
/1/ В.Г. Олифер, Н.А. Олифер. “Компьютерные сети. Принципы, технологии, протоколы.”. СПб.: Питер, 2002
/2/ Например, http://www.uinc.ru/articles/15/index.shtml
/3/ Например, http://bugtraq.ru/library/books/attack/chapter04/08.html
/4/ Эрик Коул “Руководство по защите от хакеров”. Издательский дом “Вильямс”, 2001
/5/ Стивен Норткат и др. “Анализ типовых нарушений безопасности в сетях”. Издательский дом “Вильямс”, 2001